Everything You Need to Know About Small Language Models
As we approach the end of 2024, it's clear that the rise of small language models (SLMs) has been one of the defining developments in AI this year. For those of you still stuck in LLM-world, here's a crash course on SLMs.

You’re a business leader who’s done your due diligence on generative AI and learned all the lingo. You’re fully up-to-speed on large language models (LLMs). You're heavily involved in the AI initiatives at your organization. You may even be leading those initiatives.
But... Something is bothering you.
You keep hearing about small language models (SLMs). And you kind of want to just, well, ignore them, because, a) you’re deep in your organization's LLM-based AI initiative, a project that was costly and time-consuming to implement, and why would you change direction? and b), surely a large language model is more powerful and accurate than a small one, right?
And yet… it's getting increasingly impossible to ignore the constant headlines about SLMs –in Bloomberg, Forbes, and more. You know that you need to learn about SLMs, even if it’s just to reassure yourself that you’re on the right track with LLMs. (And, yes, to be prepared to answer questions from the C-suite or your investors, when they inevitably ask you, “What's the deal with SLMs?”)
Well, fear not – we’ve made it easy for you. We’ve prepared a primer with everything you need to know about what SLMs are, how they work diffferently than LLMs, and why many organizations are making the shift from LLMs to SLMs.

What Exactly is a Small Language Model, and How Could Small Possibly Be Better than Large?
We’re all familiar with large language models (LLMs) like GPT-3 and GPT-4, which were designed for general tasks, and were trained on hundreds of billions or even trillions of tokens. And two years into the GenAI revolution, we all recognize the power of the technology, but we’re also keenly aware of the challenges involved in training, fine-tuning, and actually using LLMs: the massive number of parameters and the high computational resources required are extensive and costly, and there’s no guarantee that your data will be 100% safe.
Small language models (SLMs) have – as you likely guessed – fewer parameters compared to LLMs. Here at Arcee AI, where we have pioneered the category, we define an SLM as anything with fewer than 72B parameters.
But the “small” is not just about the lower parameter numbers. SLMs are frequently fine-tuned on small datasets – with the goal of optimizing their performance on specific tasks, making them more practical to integrate into business workflows.
SLMs Excel at Business-Specific Tasks and Workflows
Despite their smaller parameter count, SLMs are fully capable of outperforming larger generalist models when they're fine-tuned for domain-specific tasks with custom datasets.
SLMs can be taught to prioritize data important to your business use case. Task-specific training mitigates hallucinations and enhances problem-solving capabilities. Examples of this include the processing of medical, legal, and financial texts.
At Arcee AI, our SLMs routinely outrank LLMs on key benchmarks. For example, our 70B-parameter model, SuperNova, outperforms GPT-4’s massive 1.8T-parameter model when it comes to instruction-following.
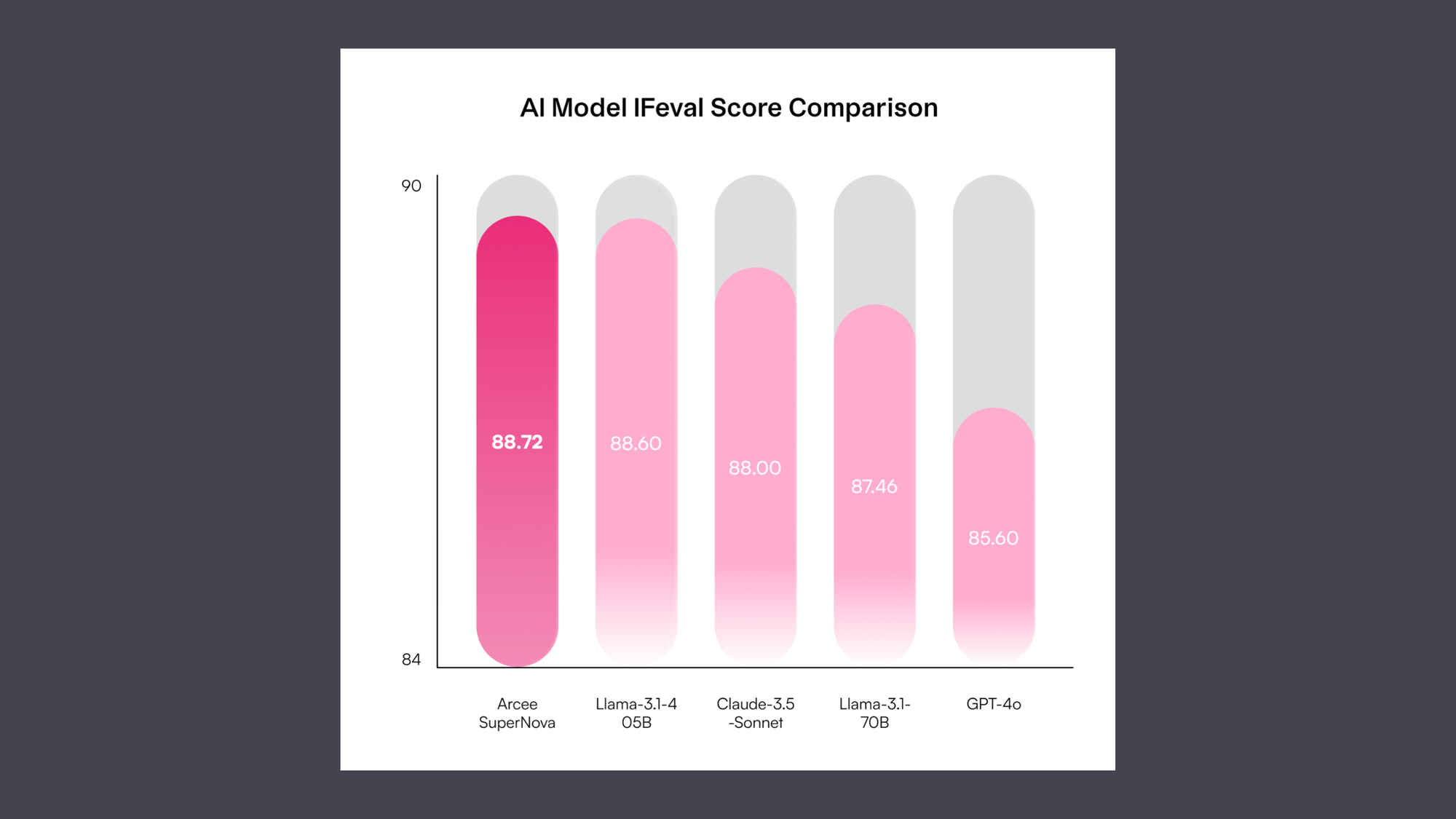
SLMs Are a Secure Solution You Own, with Less Maintenance vs. LLMs
In addition to offering superior performance to LLMs when it comes to industry-specific tasks, SLMs offer numerous other advantages.
You can deploy SLMs in any environment and own the model that drives your AI – free from vendor lock-in, and without making sacrifices when it comes to data privacy, integrity, and compliance. Your sensitive information stays within your control, avoiding third-party dependencies.
With SLMs, maintaining the hosting infrastructure tends to be much simpler than with LLMs. This is because many SLMs can fit on a single GPU, reducing the need for complex hardware setups.
This compactness allows businesses to scale more easily without the burden of extensive infrastructure changes. As a result, they not only need less ongoing maintenance, but also get improved operational efficiency.
SLMs Improve Overall Efficiency, and Lower Overall Costs
Resource efficiency is a crucial advantage of SLMs, making them particularly attractive for businesses looking to implement AI solutions across various platforms and devices.
The compact nature of SLMs makes them easier to scale across different devices and platforms, including mobile applications and devices.
SLMs empower businesses to leverage the benefits of AI with simpler infrastructure and lower costs. At Arcee AI, we’ve seen SLMs save customers up to 75% on their model training costs and more than 50% on their total deployment costs.
SLMs Lead to Truly Differentiated AI
Finally, let's focus on what we consider to be the most important advantage of SLMs: they empower you to create a truly differentiated AI offering.
How does that work, you ask?
Let us explain.
When you rely on the same foundational models as your competitors — such as GPT-4 — it’s difficult to guarantee better performance or unique capabilities compared to your competitors. But with an SLM, you can build and own a unique generative AI feature set that continuously improves based on your specific data and needs.
Take YouTube as an example: by owning its recommendation algorithm, YouTube benefits from a self-improving system. Each new user interaction provides data that enhances the recommendations, attracting even more users and reinforcing its competitive edge.
Similarly, your SLM allows you to build a self-improving data flywheel.
Like YouTube, you can collect feedback from outputs, and use that feedback to iteratively fine-tune a better model than your competitors – resulting in a personalized AI offering that's significantly more sophisticated than what your competitors get from tools like ChatGPT Enterprise and Claude Enterprise.

GenAI Market is Shifting Away from LLMs and Embracing SLMs
A great example of the market shift towards SLMs is Apple's on-device speech recognition system. According to a report by Amity Solutions, Apple has been leveraging SLMs to enhance user privacy and improve performance in their voice recognition technology.
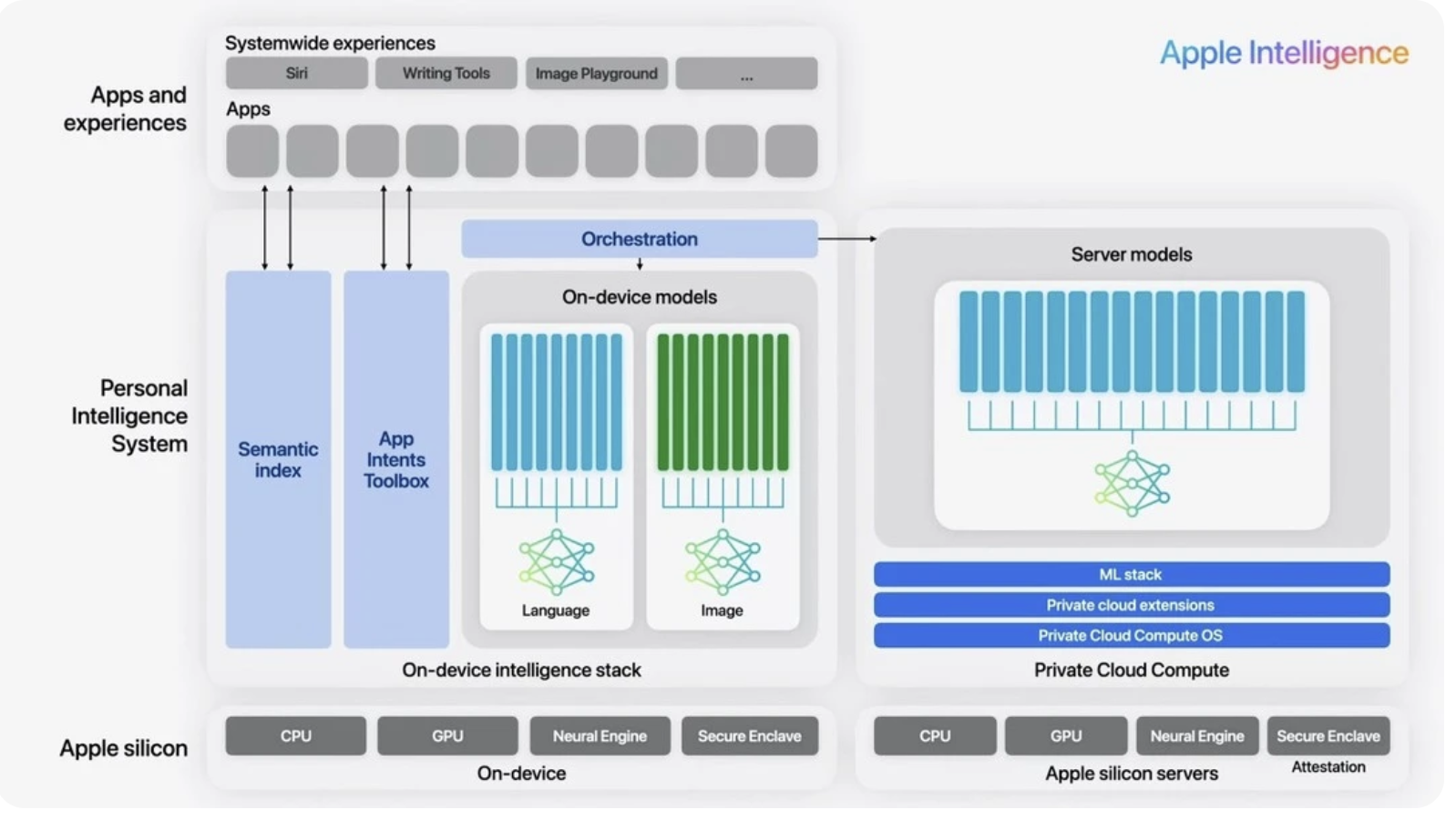
Apple's approach involves using a compact, on-device neural engine to process voice commands and transcriptions. This small model enables quick, efficient, and accurate speech recognition without sacrificing user privacy.
Are SLMs the Solution for Your Business?
Now that you've been briefed on the many advantages of SLMs over LLMs, you're likely wondering one of two things:
- If you’re just getting started with GenAI, you likely want to know how to get started with SLMs immediately. The answer is easy: just reach out to the Arcee AI team to book a demo.
- If you already have an LLM-based GenAI initiative in place, you’ll be relieved to learn that making the switch to SLMs can be a straightforward process. Reach out and we’ll tell you how businesses are migrating from tools like ChatGPT Enterprise and Claude Enterprise to Arcee AI SLMs like SuperNova.
We have a feeling that you've been convinced of the power of SLMs, and we look forward to hearing from you. 👐
Closed-Source SLMs
When ChatGPT and generative AI emerged in late 2022, the initial vision was that these cloud-based models would be the ultimate solution for all question-and-answer tasks, capable of independently performing various functions. But surprisingly, in mid-2024, The Verge reported that the release of Omni Mini caused OpenAI's API usage to double in just six weeks. Clearly, there's a LOT of demand for intelligent "small" models.This rapid shift has taken many by surprise. Who could have foreseen the market shifting so rapidly?
Open-Source SLMs
In the open-source community, the excitement around SLMs is relentless. As of September 26, more than 1 million free public models were hosted on HuggingFace, many of which are SLMs!
Distillation
Technique-wise, distillation has become all the rage in the open-source and closed-source world. We used distilliation to train our 70B model SuperNova, and rumors suggest that similar techniques were used to train closed-source models like GPT4 Omni Mini, o1-mini, Gemini 1.5 Flash, etc.
Large Language Models vs. Small Language Models
Here's a look at the key differences between LLMs and SLMs.
Size and Resource Requirements
The parameter count of large language models can range from the hundreds of billions up to the trillions. For example, GPT-3 has 175 billion parameters. This scale lets LLMs perform well on general tasks, but their size also demands substantial computational power and cloud resources, making them complex and costly to deploy.
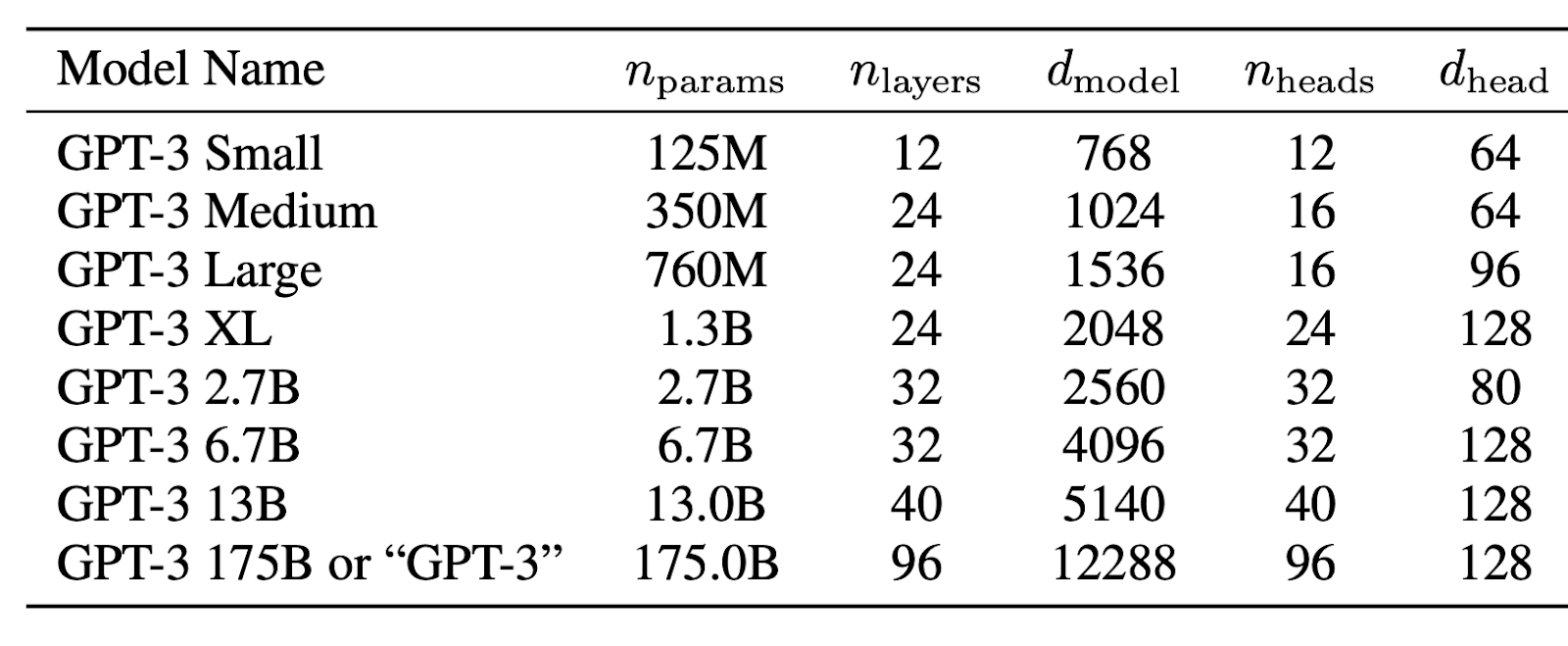
On the other hand, SLMs are designed to be more compact and efficient. They range in size from hundreds of millions to 72 billion parameters. Examples include Arcee AI’s 70B-SuperNova, Meta’s Llama-3.2-3B-Instruct, and Mistral's 8B parameter Ministral models.
While an SLM might not know who won the Grammy for Best New Artist in 1996, it could be highly helpful with business-specific tasks like suggesting the best way to onboard a new hire for your company. In addition, thanks to their reduced size and memory requirements, they can work on less powerful computers or even on edge devices.
Regarding cost, LLMs typically require significant investment, like GPT-3, which was trained using a cluster of 10,000 NVIDIA V100 GPUs and was estimated to cost around $4.6 million to train. In contrast, many SLMs can be fine-tuned on a single GPU or a small cluster of GPUs, significantly lowering training costs.
LLMs also come with higher per-token usage costs, while most SLMs, like Meta’s LlamA-3.2-3B-Instruct or Mistral’s Ministral-8B, are free or have minimal usage fees.
Memory Requirements
Just like you need enough memory on your computer to download and watch Game of Thrones, AI models need enough VRAM to load and run properly.
As a rough rule of thumb, the minimum memory required to run any language model is at least twice its parameter size in VRAM. For example, a model with 72 billion parameters would need more than 144 GB of VRAM. In practice, this often ends up being closer to 200 GB, depending on the desired context length.
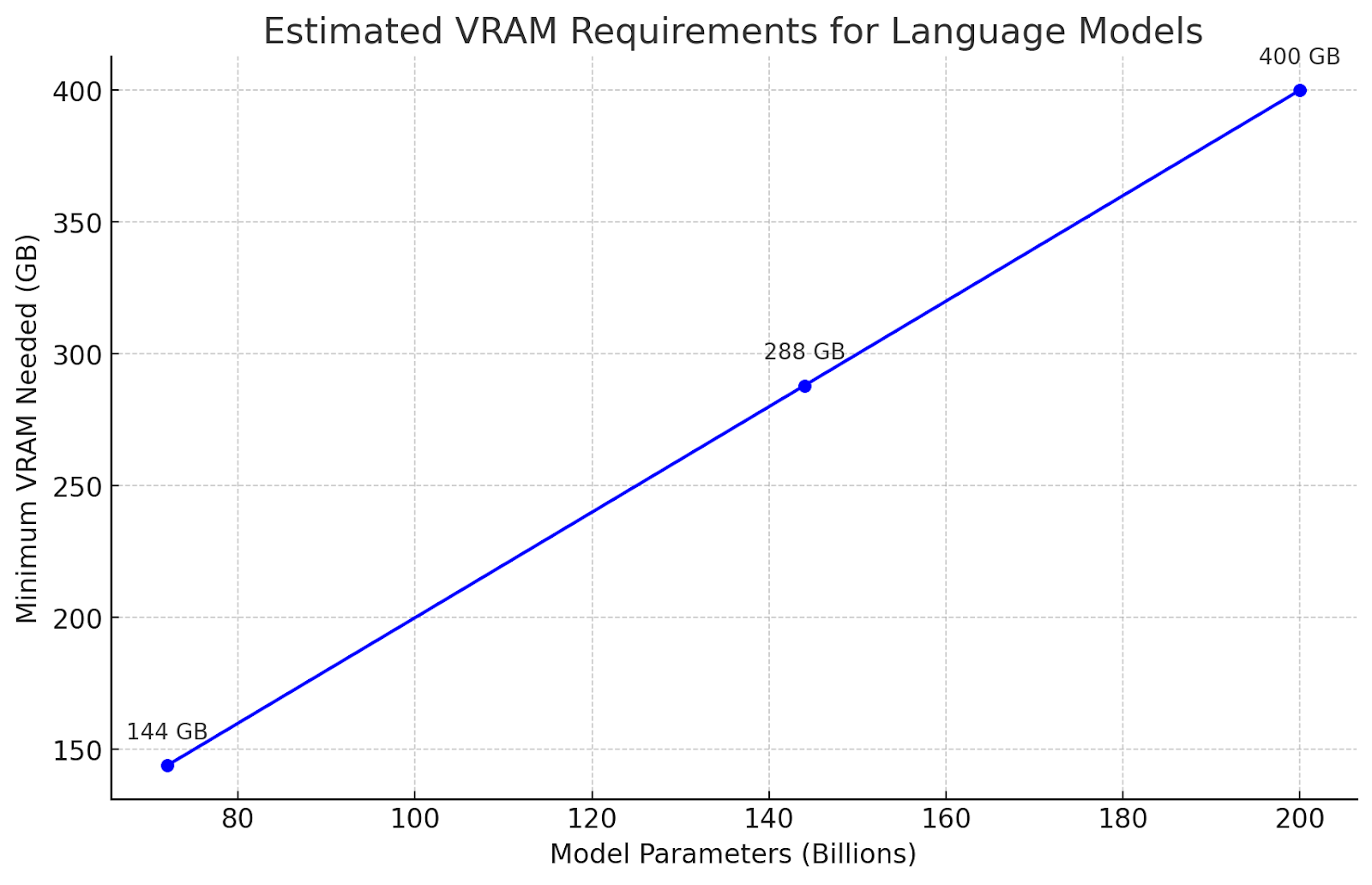
The largest recent GPUs, NVIDIA’s H100, have 80 GB of memory each.
To run the largest SLM with 72 billion parameters smoothly, you would generally need three H100s, totaling 240 GB of VRAM (80 GB x 3 = 240 GB).
On the other hand, large language models require far more VRAM. For example, a 405 billion-parameter model—still only about one-fifth the size of GPT-4—typically needs two clusters of 8 x H100 GPUs, using up to 1,280 GB of VRAM.
By contrast, even a 72B parameter SLM needs just 15% of the memory required by Llama 3.1 405B. At Arcee AI, our SMLs like SuperNova-lite typically require just a few gigabytes of memory, making them ideal for deployment on standard servers or edge devices.
Training Time
Training time increases significantly with model size, which is more than linear due to the compounded effects of computational complexity, hardware limitations, and algorithmic challenges.
Thus, there's a big difference between LLMs and SLMs:
- Large Language Models: Training an LLM can take a long time — months or even years, depending on how many GPUs you have at your disposal. For instance, training models like GPT-3 and GPT-4 required vast computational resources and large clusters of GPUs, running constantly to adjust billions or trillions of parameters.
- Small Language Models: In contrast, SLMs are much faster to train and can often be trained in days or weeks. For example, at Arcee AI, our SOTA post-training pipeline and advanced distillation techniques enable us to fine-tune SLMs in a fraction of the time it takes to fine-tune LLMs.
The faster training time and lower inference costs of custom SLMs allow businesses to maximize model performance while minimizing costs.
Quality of Outputs
Comparing the quality of outputs between LLMs and SLMs is like comparing a Swiss Army knife to a specialized tool. LLMs, like GPT-4, can handle various tasks with decent results, from writing complex essays to solving math problems.
SLMs, on the other hand, excel in specific areas they're trained for, like customer service chatbots or product recommendation systems. SLMs could efficiently answer frequently asked questions about a company's return policy with more relevant, accurate outputs when fine-tuned for that task.
Also, LLMs are generally known to excel in “zero-shot reasoning” tasks. Zero-shot reasoning refers to the model's ability to perform tasks or answer questions without specific training. However, it's important to note that many SLMs can also handle zero-shot reasoning tasks effectively.
Business Use Cases
When considering the business use cases for SLMs versus LLMs, it's essential to understand that SLMs are generally more resource-efficient, requiring less computational power and memory to run. For businesses that need to integrate natural language processing (NLP) capabilities into their products or services with minimal infrastructure overhead, SLMs provide a cost-effective solution.
Unlike consumer-focused models like OpenAI or Claude, SLMs are designed to deliver high-value results that matter most to businesses. With their smaller size, SLMs can adapt quickly and be applied to specific use cases, driving real impact and tangible outcomes. For example, the educational platform Guild ruled out closed-source LLMs due to high costs, limited support, and customization, they turned to an Arcee AI SLM.
While LLMs typically outperform SLMs for general-purpose use cases, your business probably doesn’t need a model trained to, for example, write French poetry or quote Shakespeare. Most organizations need GenAI adapted to the vocabulary of their industry and the specificities of businesses – which is why SLMs are the most appropriate solution.
FAQs about Small Language Models
What is a small language model?
Here at Arcee AI, our definition of a ‘Small’ Language Model is anything with a parameter count of 72B or less. Despite their smaller parameter count, SLMs can outperform LLMs when trained on domain-specific tasks. The reduced size makes SLMs much more cost-effective and resource-efficient and delivers lower latency than their LLM counterparts.
What is the difference between an SLM and an LLM?
The main differences are their size, computational requirements, training time, quality of output, and application scope. SLMs are smaller, require less computational power, train faster, and are often more specialized and better for business use cases. LLMs are larger, more resource-intensive, and take longer to train but are good at handling a broader range of tasks with general purpose.
What are the benefits of small language models?
Key benefits include cost efficiency, security, enhanced task-specific performance, and real differentiation for enterprise AI solutions—ideal for task-specific requirements that streamline operations and drive productivity.
What are some popular small language models?
Open-Source SLMs: Arcee-SuperNova, Arcee-SuperNova-Medius, Arcee-SuperNove-Lite, Qwen 2.5 0.5B Instruct, Llama 3.2 1B Instruct, Phi-3.5 Mini Instruct, Gemma 2 9B IT
Closed-Source SLMs: GPT4 omni mini, o1-mini, Gemini 1.5 Flash, Claude 3.5 Haiku


