Introducing Arcee’s SLM Adaptation System

At Arcee, we believe in a world of smaller, specialized models that we call SLM’s. The “S” stands for smaller, specialized, scalable, and secure. These models are grounded on your data, run entirely in your own environment, and are infinitely scalable for all your use cases.
We feel these SLM’s are better for 99% of business use cases. This strong belief is coupled with the confidence that training a model on your private data requires multiple layers of depth to achieve the results and outcomes you need for your model. Recent findings have highlighted that mere Simple Instruction tuning or LORA-type fine-tuning may not suffice, particularly in specific and knowledge-rich domains. To enhance our understanding and effectiveness in these areas, it's becoming increasingly clear that we need to advance beyond these methods and come up with innovative approaches to enhance the knowledge probing.
Our approach to domain adaptation involves a structured, four-layer process. At each of these layers, we focus on progressively enhancing the domain knowledge of the model. This systematic method ensures that the model continually advances in intelligence, specifically in relation to your private data, achieving a deeper and more refined understanding at every step.
In this article, we will walk through each layer of what we call our SLM Adaptation System.
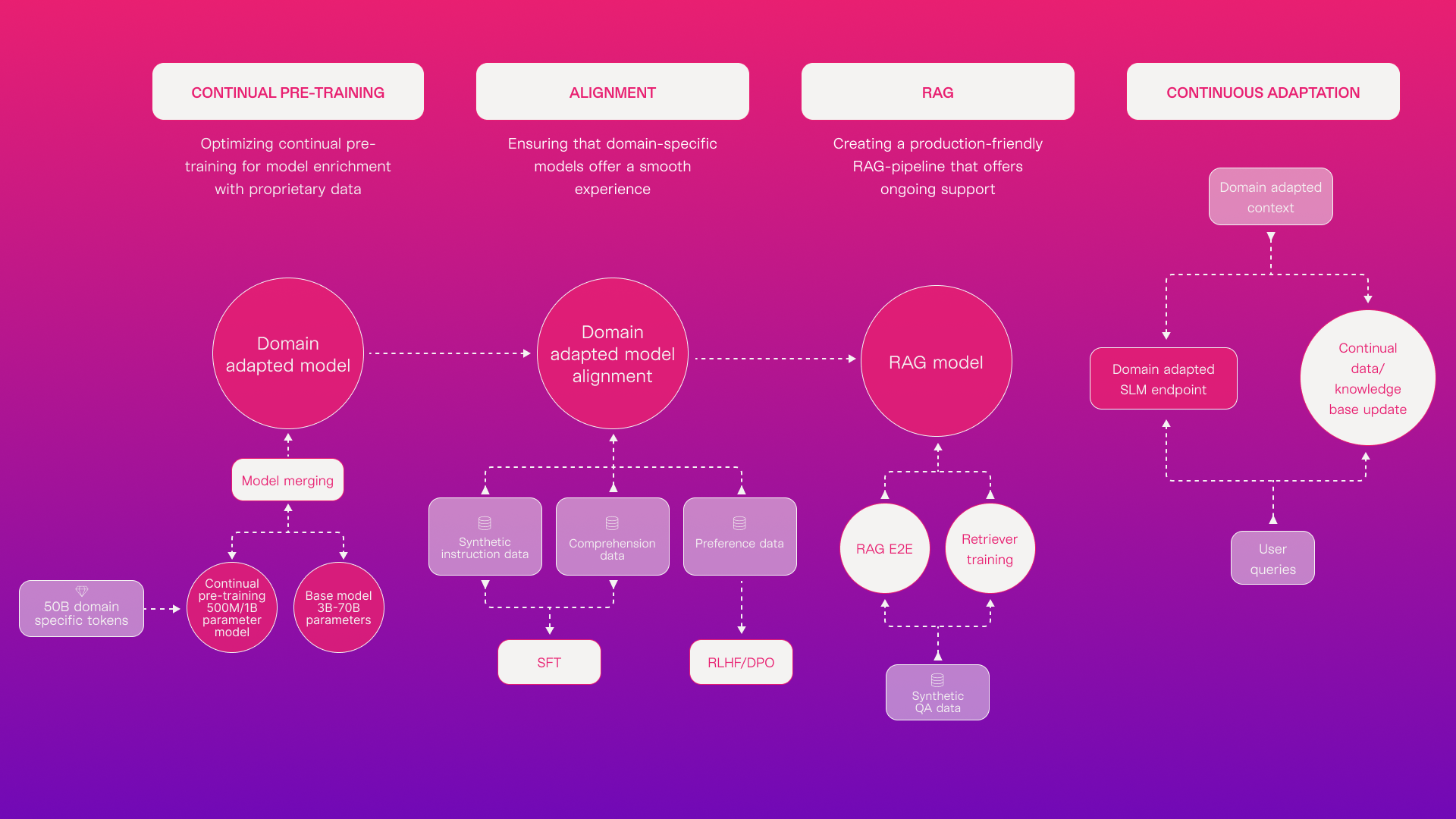
Layer 1: Domain Adaptive Continual Pretraining
In our initial phase at Arcee, we select an open-source foundational model, such as Mistral or Llama, to conduct domain adaptive continual pretraining. This process involves self-supervised training, focusing on the traditional task of next-word prediction. While the concept appears straightforward, the complexity lies in effectively training even a modestly sized 7B parameter model. Managing a dataset of 50B-100B tokens for such training can incur significant costs.
To address this, Arcee adopts an innovative strategy. We continually pre-train tiny models and then employ novel techniques for model merging. This approach allows us to provide our customers with domain-adapted models within the optimal range of 7B-13B parameters. Our methods are not only effective in achieving domain adaptivity but are also efficient and cost-reduced. This strategy highlights our commitment to delivering high-quality, domain-specific models while maintaining financial feasibility.
This delivers a trained model that is fully aware of your data and owned by you as an asset that continuously compounds in value.
Layer 2: Supervised Instruction Finetuning & Alignment with Human Preference
We now take that model that has run through the domain pretraining stage, and is now rooted and grounded in your data, and move it into an alignment layer. This layer is broken up into 2 steps.
- Supervised Instruction Fine-Tuning (SFT)
- Direct Preference Optimization (DPO), IPO, or KTO
In the Supervised Fine-Tuning (SFT) stage, we utilize gold-standard instructions, which are either specialized to your domain or synthetically generated. Fine-tuning instructions is important as it teaches the model to follow a certain set of guidelines. This process ensures that the model can perform the final tasks more effectively.
In the DPO stage, the model is polished and refined, similar to the way a diamond is carefully cut and shaped to enhance its brilliance. This DPO process aims to align the model precisely with your specific needs, uncovering its latent capabilities. The DPO process essentially sculpts the model’s responses, making them sharper, subtler, and less biased.
Layer 3: Retrieval-Augmented Generation
We now take that refined LLM and move it into a Retrieval-Augmented Generation (RAG) layer as the generator. We also then train the retriever in the RAG pipeline, so it becomes contextually aware of your data.
Incorporating a layer enhances queries by integrating contextual information. This process involves retrieving relevant data from an external knowledge base using a domain-adapted retriever. The result is then amalgamated with the original query, ensuring that the responses generated are much more informed and contextually relevant.The benefits of adding a RAG layer also allow you to dynamically add data, without the need to re-train your model.
Layer 4: Deployment & Continuous Adaptation
Finally, we now focus on deploying the model in your cloud, on your infrastructure, ensuring that data remains exclusively within your own environment. We set up the necessary infrastructure and ensure it is designed to handle the load and scale of production workloads effectively.
We also offer continuous improvements to the deployed model, assisting you in monitoring model drift, data drift, and inference performance. This monitoring helps inform decisions on when to retrain and realign the model. Additionally, it provides insights into the performance of your Retrieval-Augmented Generation (RAG) system, ranging from monitoring and correcting hallucinations to reindexing new data.
At Arcee, we believe this level of depth is needed when it comes to grounding SLM’s on proprietary data, and when stacking all these routines together, the end result is a much more accurate and aware language model. See our SLM Adaptation System in action in this video, where our CTO, Jacob Solawetz, walks through each step involved in training and deploying your SLM using Arcee's in-VPC system:
~~~~~~~~
Do you have any questions about each layer of our SLM Adaptation System, or how we can help you build your own SLM in your own cloud, with your own data? Reach out to us at sales@arcee.ai or book a demo here.


