Arcee-SuperNova: Training Pipeline and Model Composition
We trained Arcee SuperNova-70B and Arcee SuperNova-8B to be a generally intelligent Llama-3.1-405B derivatives using intelligent distillation, novel post-training, and model merging techniques.

This report details the development, training pipeline, and performance evaluation of Arcee-Llama-3.1-SuperNova, a 70B and 8B language model intended as a replacement for larger proprietary models, specifically in the context of instruction-following and human preference alignment.
Distillation Process
The distillation of Llama-3.1-405B-Instruct into Llama-3.1-70B-Instruct was one of the core components of Arcee-SuperNova's development. Initial attempts to distill the model in real-time (as defined in our DistillKit repository) proved computationally prohibitive. Specifically, the overhead required to distill 405B into 70B at training time exceeded the capabilities of our hardware stack. To overcome this, we switched to a method of logits extraction from the 405B model, applied to a carefully curated dataset of coding and mathematical samples.
Dataset Creation and Logits Compression
The initial curated dataset consisted of approximately 500 million tokens.. During the initial test runs, the total size of this dataset, with logits, was calculated to be 2.9 Petabytes, which was unsustainable for our hardware resources. To mitigate this, we developed a method of compressing logits, ultimately reducing the final dataset size to 50GB. This compression process is pivotal, enabling us to move forward with the distillation process without incurring extreme resource costs. We are currently exploring the possibility of releasing a formal paper on this distillation method, though internal discussions regarding how much to share publicly are ongoing. What we can confidently share is that you do not need all the logits per sample to perform effective distillation.
Training on Llama-3.1-70B-Instruct
The distillation into Llama-3.1-70B-Instruct was performed over the course of five days using 32 H100 GPUs, utilizing FSDP (Fully Sharded Data Parallel) for distributed training. We employed a maximum learning rate of 2e-5, with warmup stable decay (an approach developed by openbmb with their minicpm models) to maintain continued training stability. This phase of the training consisted of three epochs, with a sequence length of 4096 tokens.
Parallel Training Using Spectrum and Evol-Kit
In parallel, a separate version of Llama-3.1-70B was trained using Spectrum, targeting 35% of the highest SNR (signal-to-noise ratio) layers at a sequence length of 8192. The distributed training here was performed using DeepSpeed on a single node of 8xH100 GPUs. This model was trained on a dataset created using our EvolKit pipeline (MIT License) , which was made publicly available during the launch of SuperNova and SuperNova-Lite.
The dataset included 76,000 highly filtered samples, focusing on mathematical and coding challenges. These samples were curated from both proprietary and openly available datasets and were processed using the FineWeb-Classifier and a reranker model. We used EvolKit, which leverages a quantized version of Arcee-Nova (using GPTQ), to evolve these instructions into complex problems. The completions for these instructions were generated by a mixture of larger models - mainly Llama-3.1-405B-Instruct. .
This phase of training also consisted of three epochs, with checkpoint merging occurring every 0.5 epochs. We employed a proprietary merging technique to fuse the latest checkpoint with its predecessor, a process that acted as an effective regularization method. We observed that merged checkpoints often outperformed raw checkpoints in benchmark performance. The exact details of this merging technique will be shared in a forthcoming paper, pending internal discussions on intellectual property protection.
DPO and Final Model Merge
A third version of Llama-3.1-70B-Instruct was trained with additional Direct Preference Optimization (DPO) using qlora on a single 8xH100 node. This training run incorporated datasets that included Gemma2-Ultrafeedback-Armorm from Princeton NLP, along with several internally cleaned and filtered datasets.
The DPO was performed with a peak learning rate of 5e-7 over two epochs, with a cosine learning rate schedule. During this phase, we again utilized our checkpoint merging strategy to improve performance.
The final version of Arcee-SuperNova was produced by merging the EvolKit and DPO checkpoints first, which were then merged with the distilled Llama-3.1-70B-Instruct checkpoint. We experimented with an additional DPO tuning phase on the merged model, but this resulted in reduced performance. Consequently, we are releasing the raw merged checkpoint for SuperNova.
In addition, we are open-sourcing an 8B variant of SuperNova called SuperNova-Lite. This smaller model was trained using similar principles to its larger counterpart. However, we found that using the exact same merge order for the 8B variant did not yield equally competitive results. Ultimately, we settled on the following merge order: first, we distilled into 8B, and then conducted continued training on that checkpoint using Spectrum with our evolved instruction dataset. This checkpoint was subsequently merged with Meta-Llama-3.1-8B-Instruct, utilizing the same merging technique used for the 70B model. This process allowed SuperNova-Lite to retain many of the core instruction-following and alignment capabilities of its larger versions, while offering an efficient and lightweight alternative for certain applications.
Performance and Evaluation
Benchmark Scores
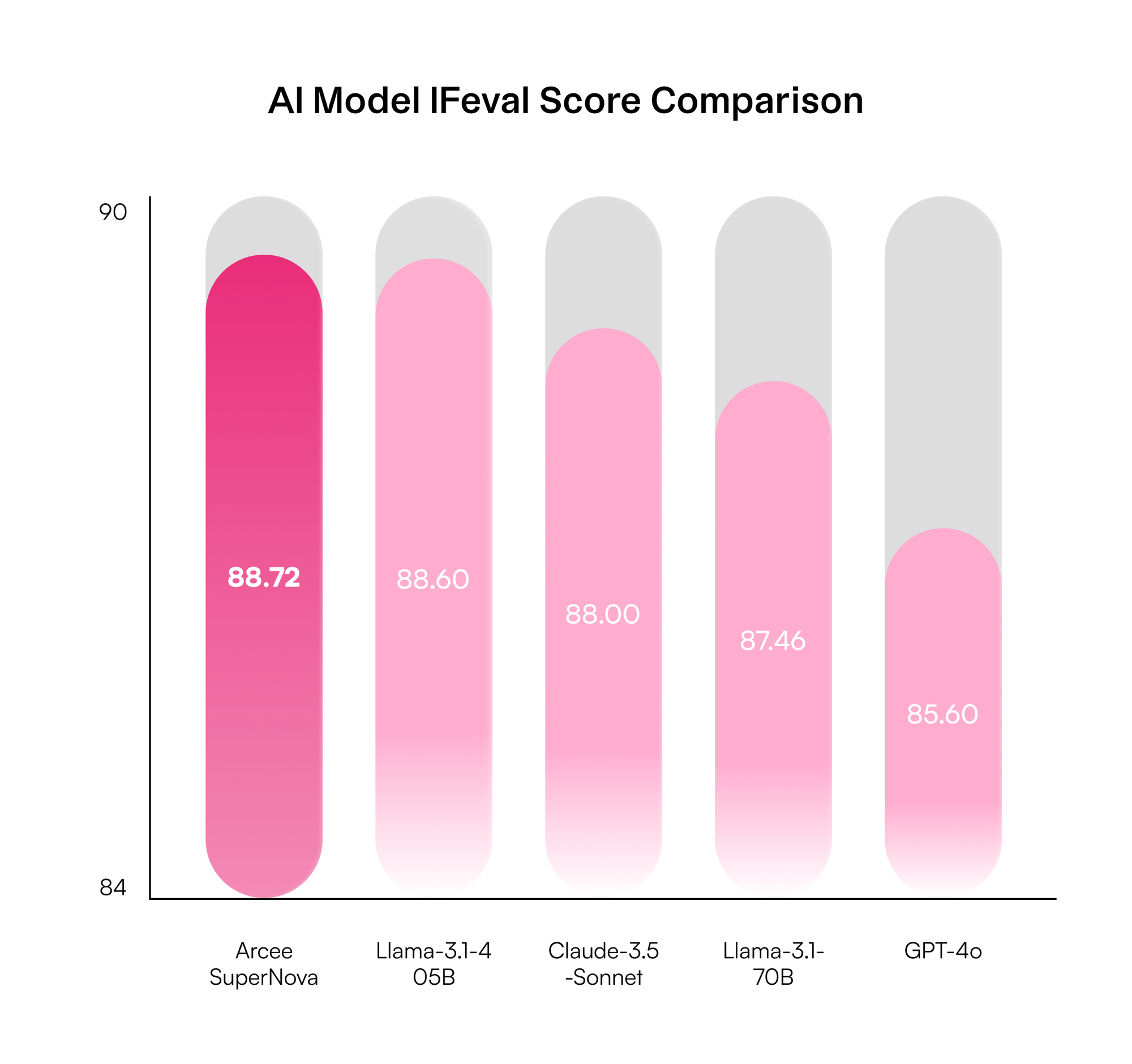
SuperNova demonstrates superior performance across multiple benchmarks, particularly excelling in instruction-following and mathematical reasoning. In if_eval, which measures obedience and predictability—key metrics critical for business applications and generative AI—SuperNova outperforms not only Llama-3.1-70B-Instruct, but also proprietary models from OpenAI and Anthropic, as well as the Llama-405B-Instruct model. This positions SuperNova as a powerful solution for organizations that require precise control over model behavior and predictable performance in production environments, directly addressing one of the major challenges in generative AI.
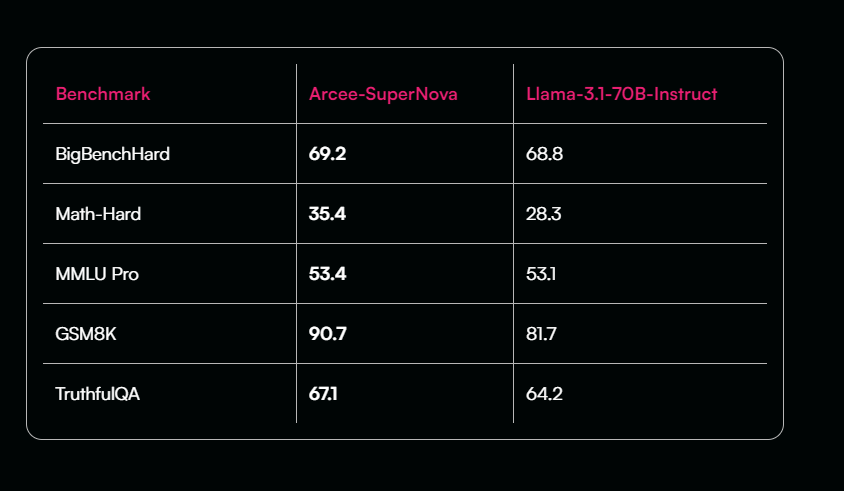
Moreover, SuperNova shows notable strengths in mathematical reasoning benchmarks like math_hard and gsm8k, consistently achieving higher scores than Llama-3.1-70B-Instruct. These improvements demonstrate its capability to handle complex, instruction-driven tasks, making it a competitive alternative to larger proprietary models such as GPT-4 and Sonnet 3.5.
That said, there are areas where SuperNova underperforms relative to Llama-3.1-70B-Instruct, notably in GPQA and MUSR. However, we are actively working on enhancing performance in these benchmarks, and SuperNova already demonstrates excellent results in key domains. For organizations looking to replace GPT-4 and Sonnets 3.5, SuperNova offers superior performance in critical business applications, with the added benefit of full control and ownership over the model’s deployment and updates, making it an ideal candidate for businesses focused on precision, reliability, and autonomy.
The results for GPQA and MUSR are as follows:
- GPQA: 35.3 (compared to 36.4 for Instruct)
- MUSR: 45.2 (compared to 45.6 for Instruct)
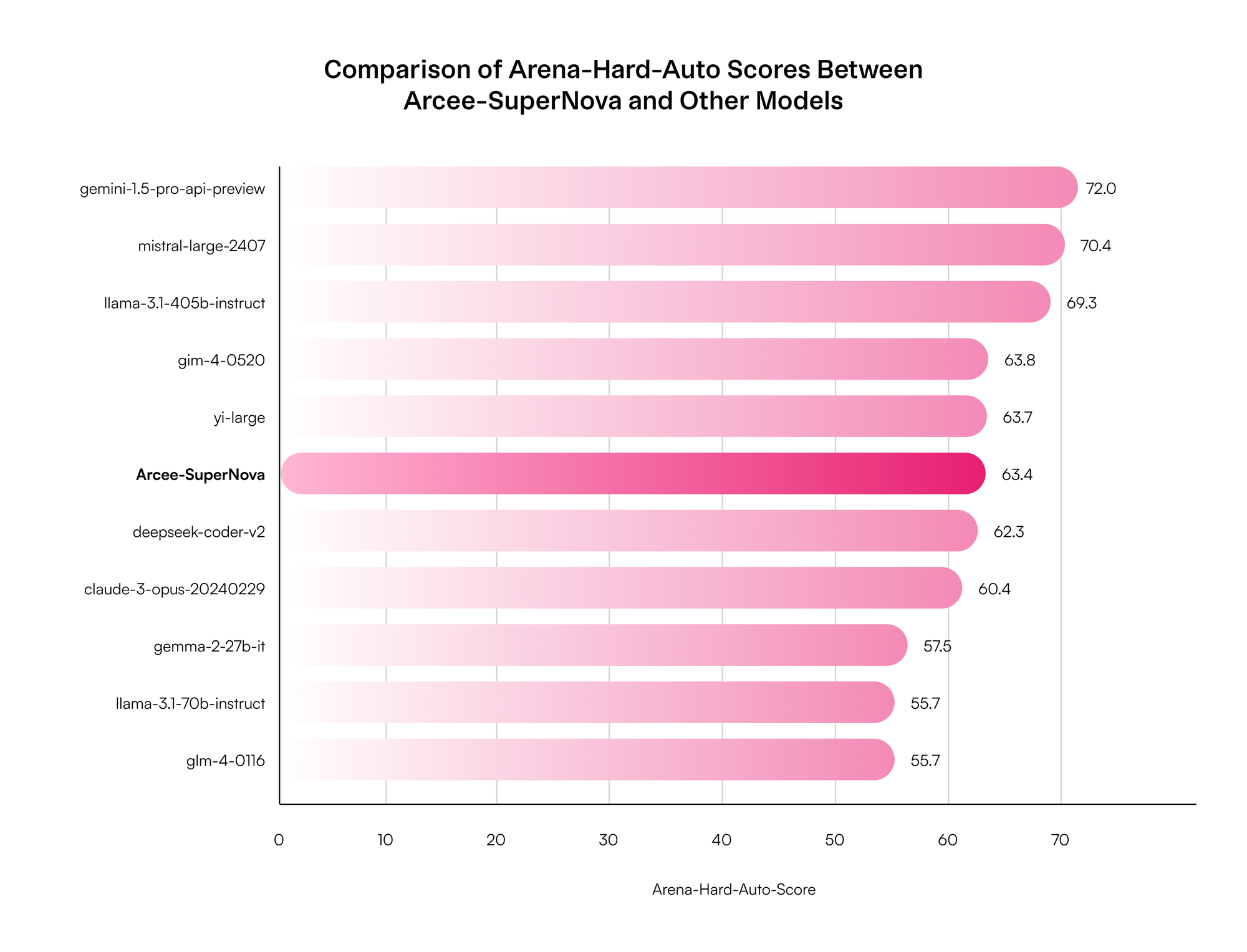
We also observed performance variability on AutoHardArena (AHA), with the pre-final merged checkpoint scoring 71.3, but showing suboptimal results in other critical areas like math, MMLU and reasoning (via BigBenchHard). This demonstrates potential sensitivity in the AHA benchmark, and thus we use this evaluation as a general guideline for human preference - but not a direct 1:1 correlation to actual human evaluations.
Evaluation Framework
All evaluations were conducted using Hugging Face’s fork of lm-evaluation-harness under the adding_all_changess branch. This fork can be found here. Verifications were also carried out using the main repository of eval harness from EleutherAI. Results were compared directly against Llama-3.1-70B-Instruct using the same evaluation pipeline, and ifeval was compared using Meta's reported results for Llama-3.1 (and other providers) from the Llama-3 report.
We are exploring ways to release deprecated SuperNova checkpoints to the research community and are actively considering research licensing for future releases.
Conclusion
Arcee-SuperNova is the culmination of several techniques developed in-house at Arcee. These include novel distillation methods, a checkpoint merging strategy, and advancements in instruction-tuning using Spectrum and EvolKit. SuperNova is a powerful and viable alternative to larger proprietary models, and we are actively working on further improving its robustness and performance across benchmarks.
While SuperNova represents a significant leap forward for 70B general models, we acknowledge the areas for improvement, particularly in specific benchmarks like GPQA and MUSR. Our goal is to make SuperNova a versatile, customer-friendly solution for instruction-following tasks, with a strong focus on security and control within customer environments.
Acknowledgments: We extend our sincere gratitude to Meta for the release of Llama-3.1. Many of our advancements in SuperNova build upon their groundbreaking work, and without it, this project would not have been possible.


