Use MergeKit to Extract LoRA Adapters from any Fine-Tuned Model
We show you how to use Arcee's MergeKit to extract LoRA adapters from fine-tuned models, then leverage the Hugging Face Hub to create a library of general and task-specific LoRA adapters.

Exciting news from Arcee! You can now extract LoRA adapters from any fine-tuned model using MergeKit.
Example:
mergekit-extract-lora 'teknium/OpenHermes-2.5-Mistral-7B' 'mistralai/Mistral-7B-v0.1' 'extracted_OpenHermes-2.5-LoRA_output_path' --rank=32
The fine-tuned model is compared against a base model, and the differences in parameter values (sometimes called task vector) are decomposed into a PEFT-compatible low-rank adapter that approximates the task vector.
When used with an adequate rank parameter, this effectively allows for compression and sparsification of fine-tuned models. Fine-tunes become megabytes instead of gigabytes, making the sharing and merging of these models easier. The lower resource requirements also make it possible to draw from a host of fine-tunes at inference time.
All existing models can be compressed with LoRA extraction. Leveraging the Hugging Face Hub, it now becomes easy to create a large library of strong general and task-specific LoRA adapters.
Such a library could be used in a dynamic merging setup, where models are merged on-the-fly, tailored to each specific request. This is just one of the many things that are made possible with this new tool.
Our Experiments
As an example, let's look at the eval results for low-rank extractions of OpenHermes 2.5.
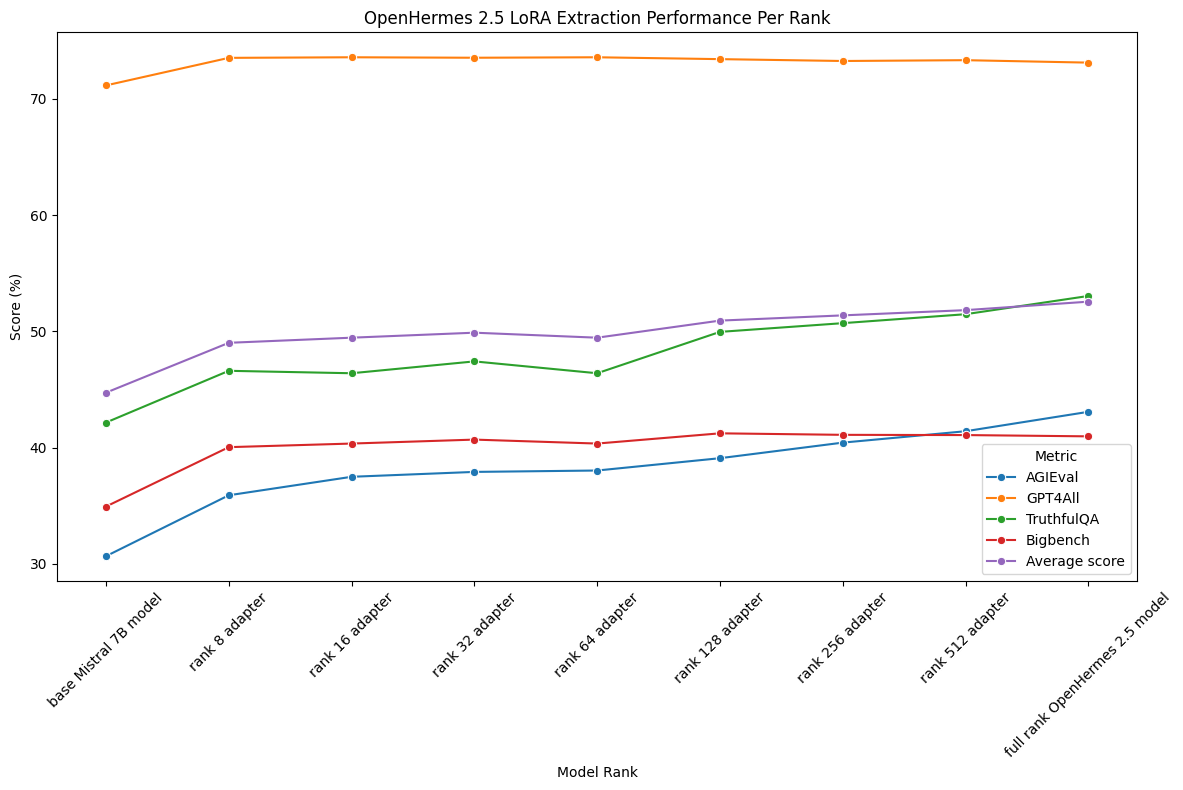
The above graph illustrates the performance of LoRA extractions on the popular Mistral-based OpenHermes 2.5 model. Remarkably, even at a low fidelity rank of 8, we achieve a 9.5% average score improvement over the Mistral base model–with only 0.46% of the parameter count of the OpenHermes model. Meanwhile, the rank 512 extraction, with 30% of the parameter count, brings us to 90% of the performance of the full model.
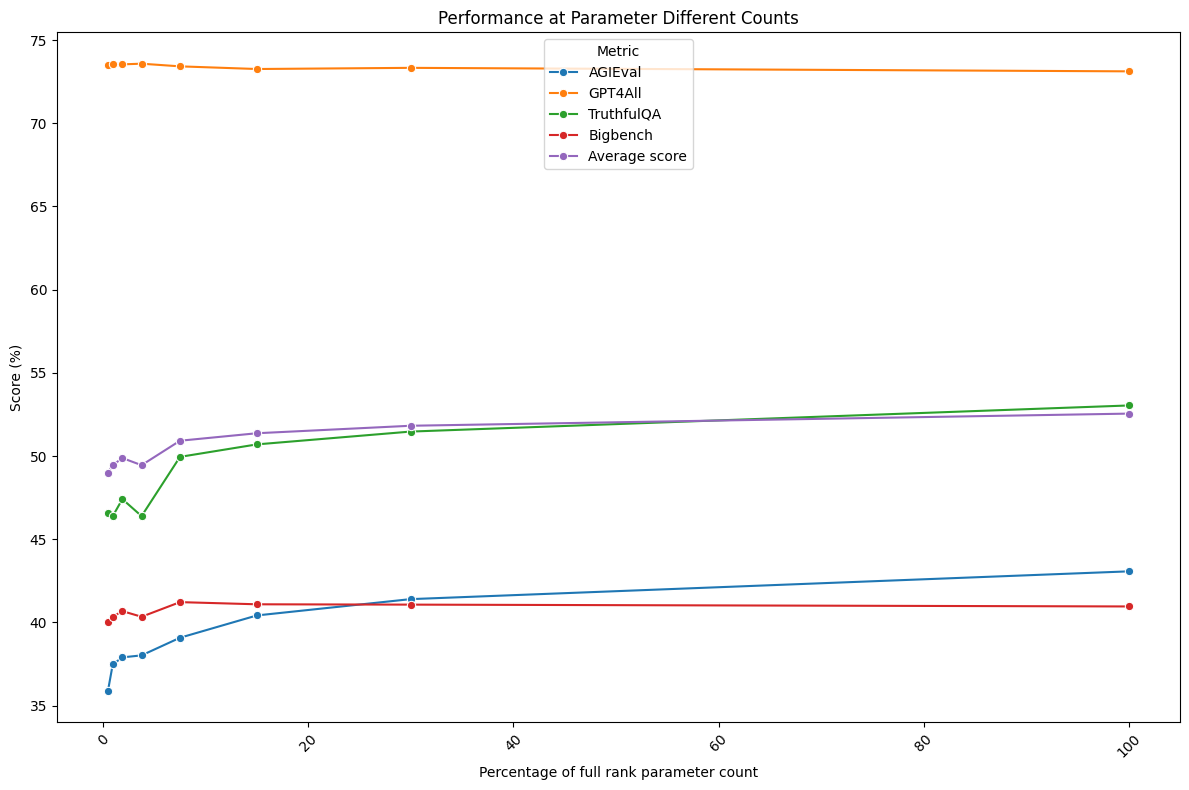
This second graph represents the same thing, but here the x-axis is expressed as the parameter count instead of rank– which is arguably what we really care about.
These results suggest that sparse low-rank approximations of fine-tuned model retain most of the capabilities of their heavier full-rank counterparts. The introduced sparsity presents a potential solution for post-hoc mitigation of common fine-tuning issues, such as catastrophic forgetting, while also facilitating efficient multi-domain adaptation through the various PEFT library merging methods.
We’re very excited to uncover all the new possibilities this presents for Model Merging, and we can't wait to see what the MergeKit community will do with it!


