The Hidden Challenges of Domain-Adapting LLMs
Adapting an LLM to a specific domain might sound straightforward, but it in fact opens a Pandora's box of challenges. Our research team explains the shortfalls of some of the most common techniques.

Adapting a Large Language Model (LLM) to a specific domain seems like a fairly straightforward task: just get the model to learn some additional data, right?
The reality, of course, is much more nuanced than that.
Here at Arcee AI, we're the leaders in building and deploying highly customized language models —what we refer to as Small Language Models or SLMs (even though they’re generally not actually that small 😂).
We’ve designed a domain adaptation pipeline that solves for the many challenges that tend to arise when you further train an LLM to customize it for a specific topic or sector.
Along the way, we’ve learned a lot about what can go wrong in domain adaptation attempts – and we’re sharing those with you here.
Navigating the Challenges of Fine-Tuning Pre-Trained Foundation Language Models
Fine-tuning of the pre-trained foundation language models has been de facto the standard approach for many years. But even in the presence of training data for fine-tuning, this process poses many challenges – and often, straightforward implementation results in poor model performance.
"Oops, I Forgot I Knew That!" – The Dilemma of Catastrophic Forgetting
First of all, the modern generation of LLMs already incorporates a lot of generic reasoning and world knowledge skills.
Classical fine-tuning, during which all model weights are updated to learn from domain-specific data, causes the model to forget some of its initial skills. This effect is called “catastrophic forgetting” and has been a known issue since the first release of the foundation language models or "LMs."

"Data Drama!" – Tackling Noisy, Templated, & Boring Domain Data
Customer domain data is often plagued with multiple issues: noisy signals, “templated” samples with a limited set of patterns, and an overall lack of diversity.
Often, even supervised domain-specific data contains use case biases that make it hard for the model to learn to generalize.
You might improve your results by working with a smaller dataset that’s undergone smart data filtering and pruning.
Being selective about the data you use for Continual Pre-Training can help to minimize an LLM’s tendency to forget its original capabilities, while improving its domain-specific performance.
One possible game-changer: generating synthetic data. But synthetic data comes with risks. These include:
• the potential spread of misinformation
• trouble aligning AI with human values
• challenges in fairly evaluating AI performance.
Synthetic data might not capture the subtle details and complexities of real human values and preferences. This gap can lead your model to learn from data that is biased, ungrounded, or misrepresentative of real-world scenarios. For example, in healthcare, too many artificial samples during training can reduce trust in diagnostic results among doctors and patients.

Breaking the Déjà Vu Cycle: The Challenge of Injecting New Knowledge
Recent results from the research community show that naive Supervised Fine-Tuning using a customer dataset can’t inject new knowledge that wasn’t already encoded in the model.
The main way for LLMs to effectively adapt to evolving customer domain information is to update their factual knowledge via Continued Pre-training on domain data.
But even this process has shown that, as the LLM eventually learns the examples with new knowledge, its tendency to produce incorrect outputs increases. LLMs trained this way struggle to answer simple questions about domain-specific documents which weave many factual statements together in a non-trivial manner.
The modern generation of LLMs has become so popular due to its universal instruction-following capabilities. Training a model with “chat” capabilities is a complex and cumbersome process, and chat skills are also prone to catastrophic forgetting.
The alignment step, along with Continual Pre-Training and Supervised Fine-Tuning, has become standard procedure to fine-tune pre-trained LLMs so that they can follow natural language instructions and serve as helpful AI assistants. It has been observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts.
Parameter-Efficient Fine-Tuning: Trade-Offs Between Efficiency and Adaptation
Are you stuck thinking that Parameter Efficient Fine-Tuning (PEFT) is the best option if you are GPU-constrained?
Think again.
Fine-tuning LLMs isn't just about having the right hardware — it's about using the right methods.
With the skyrocketing costs of fine-tuning entire modern-sized LLMs, the innovative family of PEFT methods has revolutionized the landscape. The main idea behind these methods is that all foundational models’ parameters remain unchanged, and only small additional learnable components are added to the model. This approach, while indeed providing some adaptation capabilities, still can suffer from source-domain forgetting and reduced ability to effectively learn new skills.
The Limitations of Low-Rank Adaptation (LoRA)
For instance, Lora Learns Less and Forgets Less shows that Low-Rank Adaptation (LoRA) underperforms Full Fine-Tuning (FFT) in most settings. That paper also demonstrates that LoRA keeps the fine-tuned model’s behavior close to that of the base model, with diminished source-domain forgetting and more diverse generations at inference time.
Another example is shown by How Good Are Low-bit Quantized LLAMA3 Models? An Empirical Study, which indicates that Meta’s Llama-3 demonstrates superior performance post-quantization but suffers significant degradation – which poses challenges for deployment in resource-limited environments. This finding highlights substantial opportunities for growth and improvement in low-bit quantization.
Instruction-Tuning (IT) Challenges and the Power of Continual Pre-Training
A recent study shows that Instruction-Tuning (IT) with PEFT models can learn response initiation, but the models extract most of the information from the pre-trained knowledge. The models also learn pattern-copying of stylistic tokens from the domain-specific dataset. Since this technique makes the model borrow tokens from the dataset as a pattern-copying event, it generally hurts the factual correctness of the responses and increases hallucination. Their study indicates that IT fails to enhance knowledge or skills in LLMs.
LoRA fine-tuning is limited to learning response initiation and style tokens, while FFT leads to knowledge degradation. Their findings reveal that responses generated solely from pre-trained knowledge consistently outperform responses by models that learn any form of new knowledge from IT on open-source datasets. These observations underscore the power of Continual Pre-Training in injecting new knowledge and skills into a model.
Mastering Hyperparameter Tuning for Effective Domain Adaptation
Any phase of domain adaptation requires experimenting with hyperparameters tuned to find an appropriate trade-off between forgetting and adaptation to the new data.
Although the research community provides reasonable starting values for these hyperparameters, some probing and experimentation is still required to adjust to specific data. For example, to properly adjust the parameters, one needs to identify how different your data is vs. the data used for the base model pre-training.
Model Drift: When AI Takes a Wrong Turn
After domain adaptation and alignment, the model's performance might degrade over time or across different domains. This phenomenon is called “model drift.” There are three different distributional shifts that can cause model drift.
Temporal shift
Temporal shift refers to the distributional shifts occurring over time, which occur when the input variables no longer match the target variables. There are a variety of categories that can result in temporal shift:
- Recurring: the shift reoccurs on a regular basis (e.g., shopping behavior based on the season)
- Sudden: an unexpected change resulting in the shift of output (e.g., the sudden decrease in restaurant visits after the COVID-19 pandemic)
- Gradual: a change to an expected pace, exemplified by the evolution of fraud detection strategies as both fraud detection and fraud attempts become more sophisticated over time.
Content shift
Content shift refers to the LLM learning from different fields. It’s based on the fact of changing the distribution of the input data, such as changing the field of knowledge from Chemistry to Biology.
Language shift
Language shift happens when the model learns different language corpora and the change occurs in the data pipeline (e.g., changing the data language from English to German).
Detecting and addressing model drift is crucial because an AI model's accuracy can degrade quickly after deployment due to the divergence of production data from the model's training data, leading to incorrect predictions and significant risk exposure. Deploying a model is just the beginning; for sustained performance, long-term monitoring is essential.
Hallucinations and Retrieval Augmented Generation (RAG)
One of the most popular ways to inject domain data into a model is not to do any weights tuning, but instead, to just insert relevant context to the prompt. This so-called Retrieval Augmented Generation approach has become a de facto standard for any private context data LLM usage. It also reduces hallucinations even for the text data which was used in the model’s pre-training stage, since it explicitly reminds the model about the knowledge which it might have already forgotten. This often leads to use cases where the original customer’s query is augmented with relevant contextual information using a separate search service.
That adds a ton of new challenges and costs to the LLM usage pipeline (e.g., searching database and engine, parsing the documents, deciding how to best split the content into search contexts, etc.).
The relevant context search is usually done with the help of a separate embedding model, for which domain adaptation is yet another challenge for any production use. General purpose embedding models can provide a decent initial performance for relatively short corpora, but our own research at Arcee AI suggests that the representation model also benefits from in-domain fine-tuning.
Usage of generative LLMs in the RAG setup changes the input patterns and introduces additional difficulties for the model to be able to handle a bunch of relevant and non-relevant information in the prompt. It was found to be beneficial for the LLM training to incorporate RAG-like input prompts in the pre-training process. Moreover, to avoid hallucinations, it can sometimes be helpful to incorporate RAG-like training samples with no relevant context.
Unveiling the Secrets of LLM Evaluation: Are We Really Assessing True Capabilities?
Have you ever wondered how we truly measure the power of LLMs? How can we be sure that their impressive performance isn't just a result of memorizing data they have already seen?
Evaluation is the critical step that allows us to understand both the general capabilities and domain-specific proficiencies of an LLM. And here's the key: selecting the right benchmarks is essential to avoid misleading results.
The Contamination Challenge
Data contamination can make the evaluation process a real puzzle! When test data appears in the training data, it's often challenging to discern whether the model's performance is due to genuine understanding or just plain memorization. With many benchmarks readily available on the internet, it’s probable that the LLM has encountered these benchmarks during training. So, it’s hard to differentiate between contamination and true generalization.
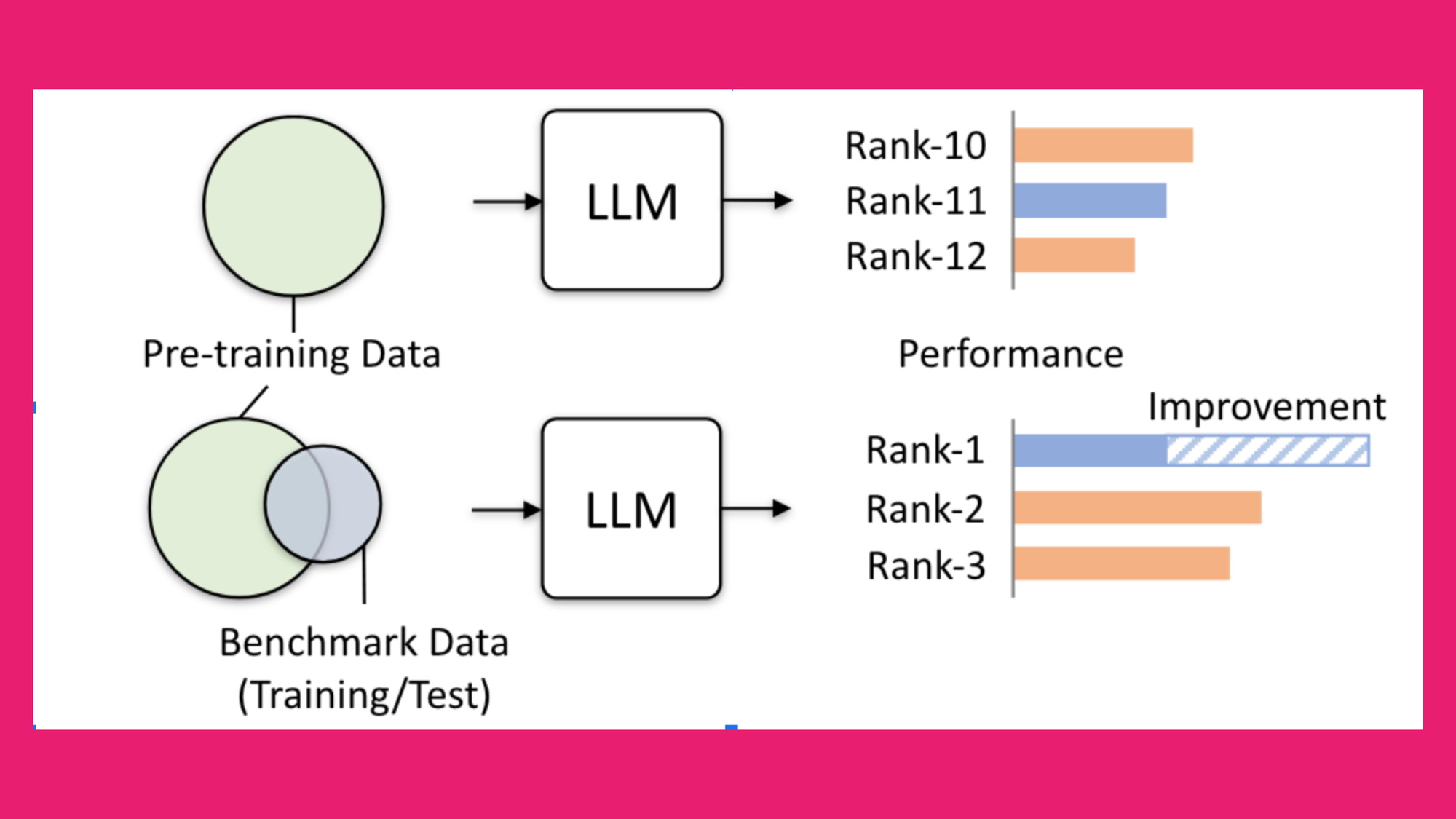
Benchmarking: More Than Just a Test
Have you ever questioned the significance of domain-specific benchmarking systems?
Imagine a legal research provider claiming their AI eliminates hallucinations, yet their evaluations remain unpublished. This lack of transparency is problematic. Despite advancements, models still produce incorrect, fabricated, or incomplete information. For example, a recent study revealed that some legal language models hallucinate 17% to 33% of the time – meanwhile, their legal research providers claim their RAG-based methods eliminate hallucinations! While AI tools in legal research aim to reduce hallucinations compared to general-purpose AI systems, they still face significant challenges. This study underscores the necessity of a well-designed domain-specific benchmark. It also highlights the potential need for human intervention to ensure accurate and responsible evaluation, supervision, and verification of AI outputs – and as we all know, human intervention comes at a high financial cost.

Domain-Adaptation: Solutions must address a multitude of challenges
While designing the overall domain adaptation process of LLMs, it's necessary to account for all of the challenges we've discussed here. Here at, Arcee AI the LLM training and merging pipeline that we've developed fills the gaps – taking on all of these challenges and ensuring robust and efficient model adaptation across various domains. To learn more or if you have specific questions about domain adaptation, you can reach out to the authors: malikeh@arcee.ai, shahrzad@arcee.ai, & vlad@arcee.ai