Optimizing LLM Training with Spectrum
Here at Arcee AI, we're the pioneers of training performant and efficient LLMs with Model Merging... And now we bring you *yet another* cutting-edge technique that also dramatically optimizes your training and improves your models.

At Arcee AI, we're committed to pioneering innovative strategies to enhance the efficiency and efficacy of models trained on our platform. One significant innovation we have integrated into our processes is Spectrum, a method for optimizing the training of large language models (LLMs). Here, we discuss what Spectrum is, its operational mechanics, and how it has helped evolve our model training methodologies.
What is Spectrum?
Spectrum is a novel training methodology designed to optimize the training process of LLMs by selectively training specific layers based on their signal-to-noise ratio (SNR). The core concept of Spectrum is straightforward yet highly effective. Instead of updating every layer of the model during training, Spectrum identifies and prioritizes the layers that contribute most significantly to performance improvements (high SNR), while the layers with low SNR remain frozen.
This targeted training approach offers several key advantages:
- Reduced Training Time: By concentrating the training effort on a subset of the model's layers, Spectrum significantly reduces the computational resources and time required for training LLMs.
- Memory Efficiency: Selective layer training results in lower memory consumption, enabling the handling of larger models or batch sizes.
- Minimized Catastrophic Forgetting: Freezing specific layers helps retain the knowledge already embedded in the model, thereby reducing the risk of catastrophic forgetting.
How Does Spectrum Work?
The Spectrum methodology can be broken down into the following steps:
- SNR Analysis: In the initial training phase, Spectrum assesses the signal-to-noise ratio for each model layer. The SNR measures the useful information each layer contributes relative to the noise.
- Layer Selection: Based on the SNR analysis, layers are categorized into high and low SNR groups. Layers with high SNR are deemed critical for training and are selected for updates.
- Targeted Training: Only the high SNR layers undergo active training, while the low SNR layers are kept frozen.
Spectrum in Action at Arcee AI
At Arcee AI, we have seamlessly integrated Spectrum into our model training pipeline to optimize both the Continual Pre-Training (CPT) and Supervised Fine-Tuning phases. Here's how Spectrum has transformed our training process:
- Increased Training Speed: With Spectrum, we have accelerated our training process by up to 42%. Focusing on the most impactful layers reduces the overall computational workload without sacrificing model performance.
- Maintained Quality: Our models uphold high-performance standards despite the accelerated training schedule. The selective training ensures that the critical parts of the model are tuned, preserving the quality and accuracy of our LLMs.
- Enhanced Memory Efficiency: Reducing active layers during training translates to lower memory usage. This efficiency allows us to train larger models or increase batch sizes, improving our training throughput.
- Reduced Catastrophic Forgetting: One of the significant advantages of Spectrum is its ability to minimize catastrophic forgetting. By keeping specific layers frozen, the existing knowledge within the model is preserved – ensuring that new training does not overwrite previously learned information.
Training Qwen2-72B and Llama-3-70B on a Single H100 Node
One of the most compelling demonstrations of Spectrum's capabilities at Arcee AI is its application in the Continual Pre-Training of massive models like Qwen2-72B and Llama-3-70B on a single H100 node.
Traditionally, training such large models on a single node would necessitate significant performance trade-offs. However, with Spectrum, we have achieved this feat while maintaining performance.
Evaluation Results
To quantify the impact of Spectrum, we conducted extensive evaluations across various metrics. Here are some highlights:
- Training Time Reduction: Across multiple training runs, Spectrum consistently reduced the training time by an average of 35%, with some training pipelines seeing a 42% increase, allowing us to achieve faster iterations and quicker deployment of models.
- Memory Usage: Spectrum's selective layer training reduced memory usage by up to 36%, enabling the training of larger models or increased batch sizes without additional hardware resources.
Performance Metrics: Despite the reduced training time and memory usage, models trained with Spectrum showed no significant degradation in performance. Some models demonstrated improved performance due to the targeted training of high-impact layers. Our Arcee-Spark and Arcee-Agent models were trained entirely within our platform, using Spectrum to optimize training.
In their paper, the authors behind Spectrum (including Lucas Atkins and Fernando Fernandes Neto from Arcee) compared Spectrum against QLoRA and full fine-tuning techniques. We have found that these findings extend to Continual Pre-Training (CPT).
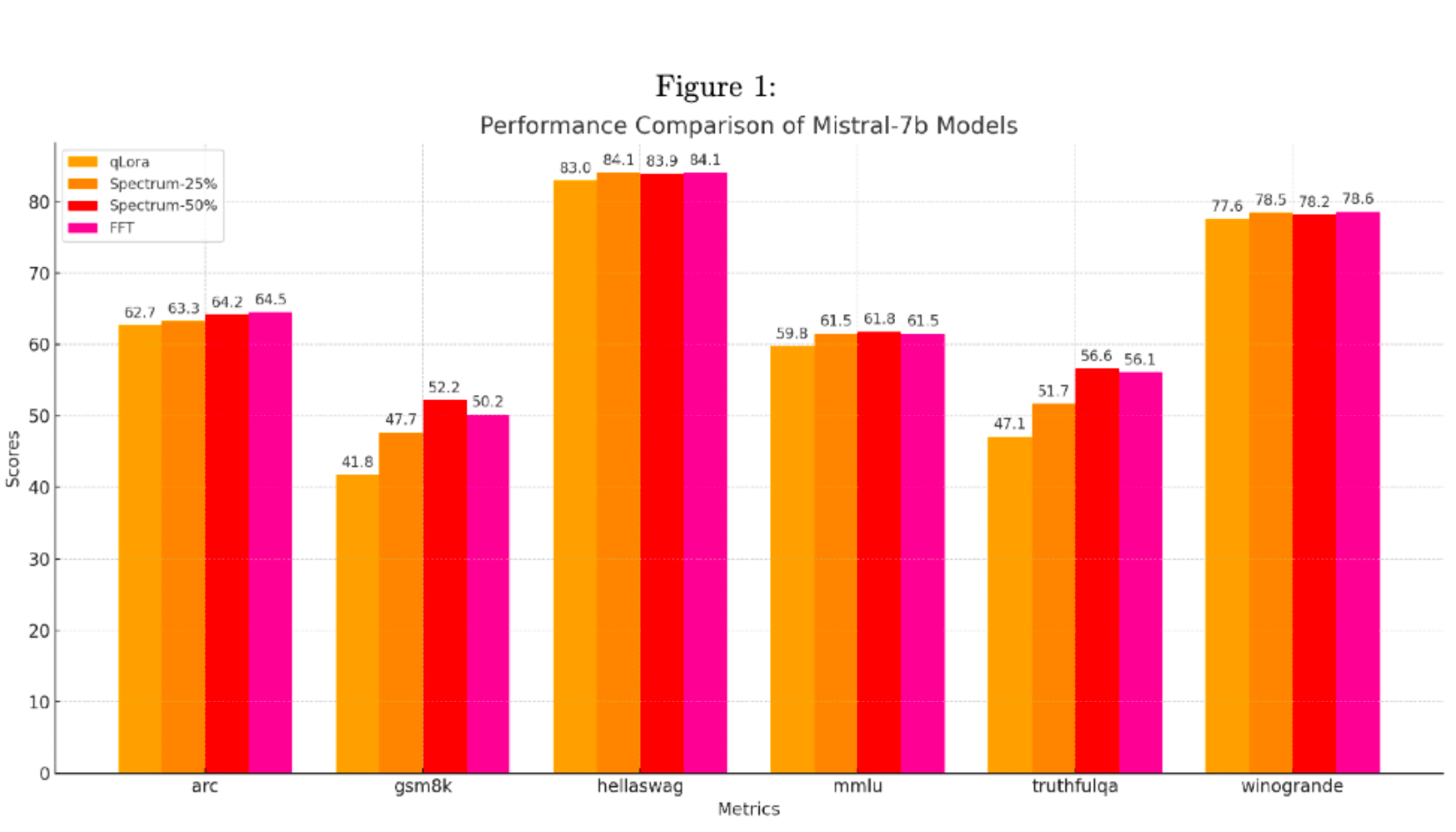
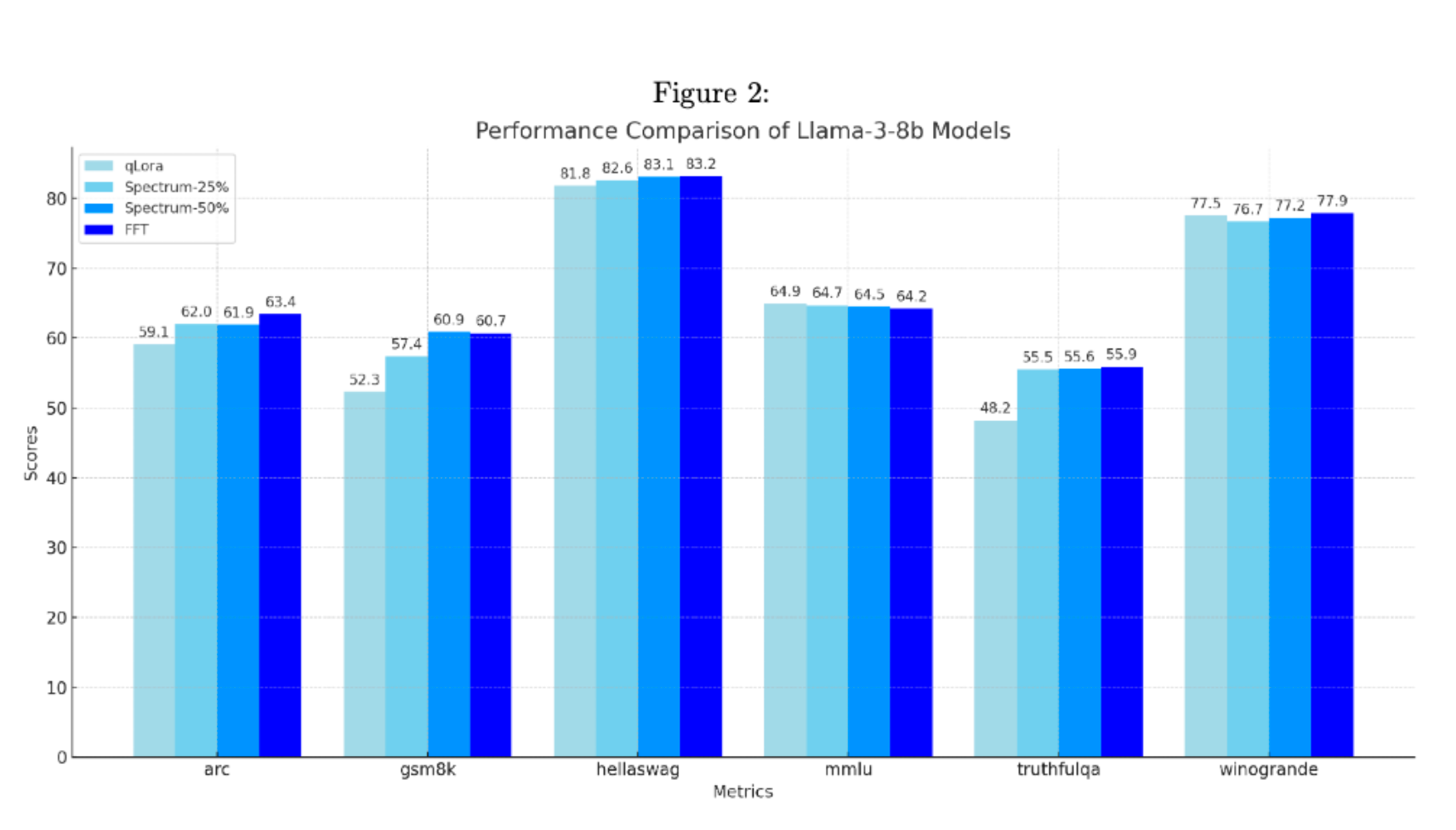
Spectrum will remain a vital component of our toolkit, empowering us to deliver top-tier models that meet our clients' needs. This optimization has streamlined our current training processes and paved the way for future advancements, ensuring we remain at the cutting-edge of LLM training.


