Introducing the Ultimate SEC LLM: Revolutionizing Financial Insights
We built Llama-3-SEC upon the powerful Meta-Llama-3-70B-Instruct model, with the goal of providing unparalleled insights and analysis capabilities for financial professionals, investors, researchers, and anyone working with SEC filings and related financial data.

The Vital Role of Domain Adaptation and SEC Data Chat Agents
In the rapidly-evolving landscape of language models, it has became increasingly important to be able to train models for specific topics and sectors. Domain-specific large language models (LLMs) are fine-tuned to understand and generate text within particular fields, significantly enhancing their performance and relevance. This specialized training process allows these models to leverage vast amounts of domain-specific data to improve their accuracy and utility.
The base model for our work, Meta-Llama-3-70B-Instruct, has significantly impacted the LLM community with its robust capabilities and adaptability. It serves as a solid foundation for our domain-specific enhancements, particularly in integrating U.S. Securities and Exchange Commission (SEC) data to create a specialized chat agent.
SEC data encompasses a wide range of financial and regulatory information submitted by publicly-traded companies. This data includes quarterly and annual reports, filings related to insider trading, proxy statements, and other critical documents. SEC data is important for investors, analysts, and regulators as it provides transparent and detailed insights into a company's financial health, operational performance, and corporate governance.
Here are just some of the many potential use cases of an SEC Chat Agent:
- Investment Analysis: Investors utilize SEC data to make informed decisions by analyzing a company’s financial statements, earnings reports, and market disclosures.
- Risk Management: Financial institutions and analysts assess the risk profiles of companies by examining their SEC filings, enabling better risk mitigation strategies.
- Regulatory Compliance: Regulators and compliance officers use SEC data to ensure that companies adhere to financial and operational regulations, identifying potential violations and areas of concern.
- Corporate Governance: Researchers and policymakers study SEC filings to understand corporate governance practices and promote transparency and accountability in the corporate sector.
- Market Research: Market analysts and strategists use SEC data to track industry trends, competitive positioning, and market opportunities.
By leveraging SEC data, we have enhanced the Meta-Llama-3-70B-Instruct model – creating a powerful domain-specific chat model that can be used for financial analysis, compliance monitoring, and strategic decision-making within the financial sector. This transformation underscores the importance of training models in specific domains, demonstrating how specialized data integration can significantly enhance a model's capabilities.
The result: the Ultimate SEC Data Chat Agent, providing users with unparalleled insights and analysis capabilities.
In this release, we're sharing two models. The first model underwent Continual Pre-Training (CPT) and merging phases, with all the above-discussed insights and evaluations provided for the CPT and then merged models. The CPT model was trained with 20B tokens (the final model is still in training), and we plan to release additional checkpoints soon.
For the community, we're also sharing a Supervised Fine-Tuned (SFT) version with the ChatML prompt template. This SFT model was trained on a mixture of custom domain-specific and general open-source datasets, utilizing Spectrum for efficient training on an 8xH100 node
Data Acquisition and Pre-Processing
Our process for reading, parsing, extracting, cleaning, and storing pure text data from SEC filings involves several key steps. We use libraries like boto3 for AWS S3 interactions, trafilatura for text extraction, and various components from Hugging Face's DataTrove library.
First, we read data from AWS S3, specifically targeting .txt files. HTML documents are processed using trafilatura to extract text and convert it to Markdown format. This ensures easier processing and analysis. We then filter documents based on acceptable formats, such as Markdown and plaintext, while avoiding non-textual content like PDFs, Excel files, and ZIP archives for model training.
Datatrove processing pipelines are used to streamline data handling, enabling efficient processing of large volumes of SEC filings by executing stages such as reading, cleaning, filtering, and writing concurrently. Finally, the cleaned files are saved back to the S3 bucket, organized under a specified prefix for easy access and further analysis. This comprehensive preprocessing pipeline ensures high-quality input for our model's training.
Continual Pre-Training (CPT) with Megatron-Core
Training a model at the scale of 70 billion parameters presents significant challenges in terms of efficiency and scalability. While many training frameworks exist, they often fall short when handling such large models and token counts. To address this, we opted for Megatron, leveraging its advanced parallelization capabilities – including model parallelism, tensor parallelism, and sequence parallelism.
Our training was conducted on a cutting-edge AWS SageMaker HyperPod cluster, consisting of 4 nodes, each equipped with 32 H100 GPUs. This robust setup was essential for the efficient and scalable training of our massive dataset. Usually, SLURM clusters are particularly challenging to set up but are crucial for our needs. However, SageMaker HyperPod was easy to configure and had already been tested with Megatron, making it an ideal choice for our training environment. SageMaker HyperPod ensures streamlined distributed training for large clusters, optimizing the utilization of compute, memory, and network resources. It provides a resilient training environment by repairing faulty instances. Its FSx drive ensures faster saving, and the InfiniBand network facilitates faster communication. Additionally, it can integrate with dashboards like Grafana for better monitoring. We integrated everything into the Arcee training platform to create a seamless training experience.
In the CPT layer, we mixed 70B token SEC data with a general sample of Together AI’s RedPijama data of 1B tokens by following prior work. This approach has allowed us to maintain a high level of generalization while benefiting from domain-specific data. The total estimated time to train using Megatron on this distributed training setup was 31 days, highlighting the significant computational effort involved.
During our training, we initially processed 70B tokens. However, in this release, we're sharing the CPT model trained with 20B tokens (since the 70B model is still being trained). We plan to release additional checkpoints in the future.
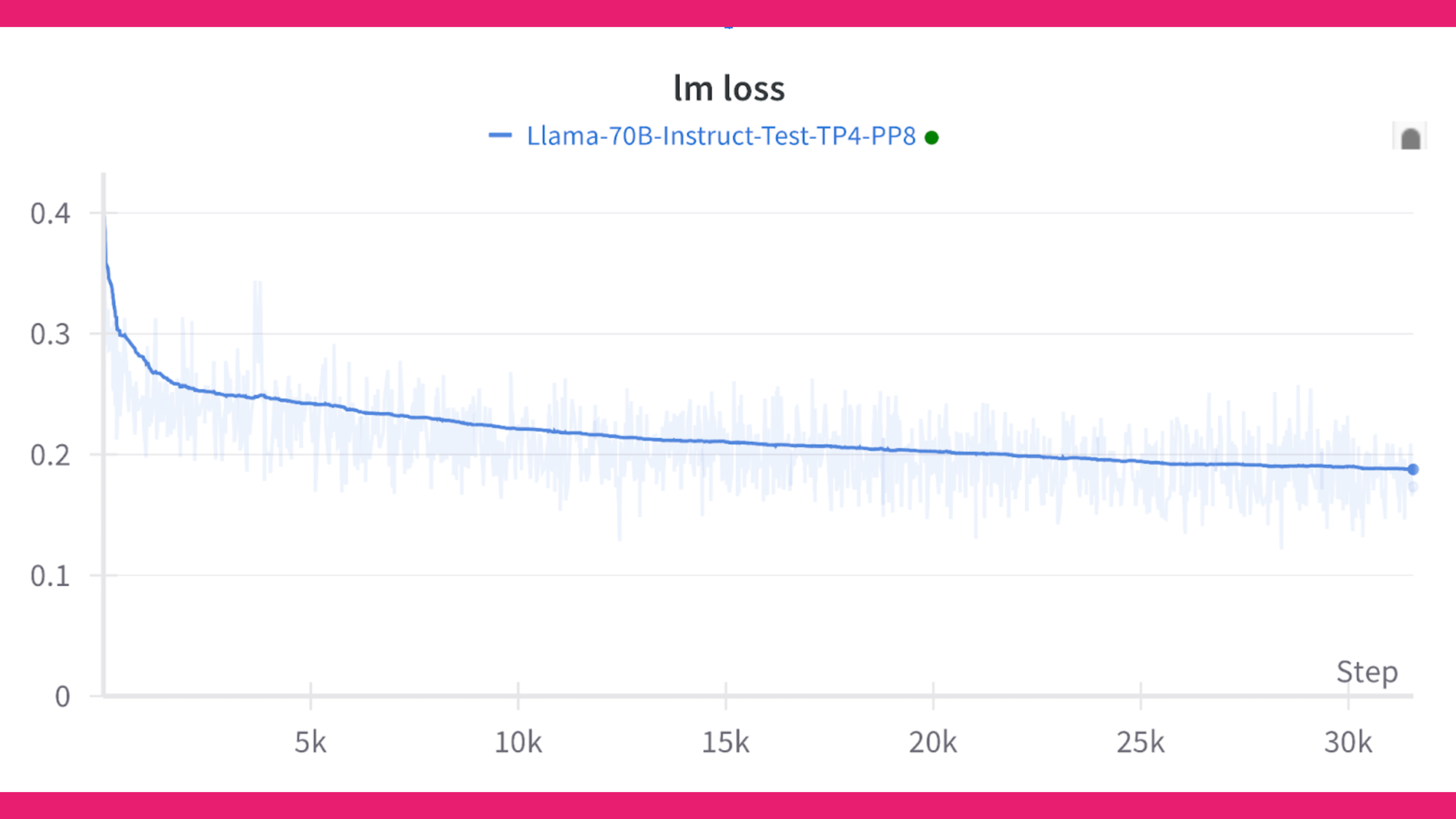
Post-CPT Model Merging with MergeKit
To mitigate the issue of catastrophic forgetting that can occur during Continual Pre-Training, we employed TIES merging from the Arcee Mergekit toolkit. Drawing on prior work, we merged the CPT models back into the instruct version. The primary goal of the merge was to retain the instructive capabilities of the base model while integrating the specialized knowledge acquired during CPT.
TIES merging is a natural fit here and allows us to maintain a balance between the instruct model's foundational understanding and the CPT model’s enhanced domain-specific expertise, resulting in a more robust and versatile language model. We have shared the details of the merge config on our Hugging Face model card.
Evaluations
To ensure the robustness of our model, we conducted thorough evaluations on both domain-specific and general benchmarks. Domain-specific evaluations are crucial to assess our model's performance within its targeted domain. However, general evaluations are equally important to ensure no catastrophic forgetting of the model's original capabilities.
In every evaluation, we compared the following models with each other:
- Llama-70B-Instruct (meta-llama/Meta-Llama-3-70B-Instruct): The original instruct model released by Meta
- Llama-70B-CPT: The Llama-70B-Instruct model after Continual Pre-Training, with the checkpoint saved after seeing 20B tokens
- Llama-70B-CPT-Merge: The Llama-70B-CPT model merged with the original Llama-70B-Instruct model using the TIES method.
Domain-Specific Evaluations Metrics
Domain-specific perplexity is crucial for evaluating a model's performance within its targeted domain, ensuring effective adaptation to domain data. Tracking perplexity changes helps assess the impact of Continual Pre-Training (CPT) and domain-specific improvements.
Figure 1 below illustrates domain-specific perplexity measurements for different model variants, highlighting the impact of CPT and Model Merging on SEC data performance.
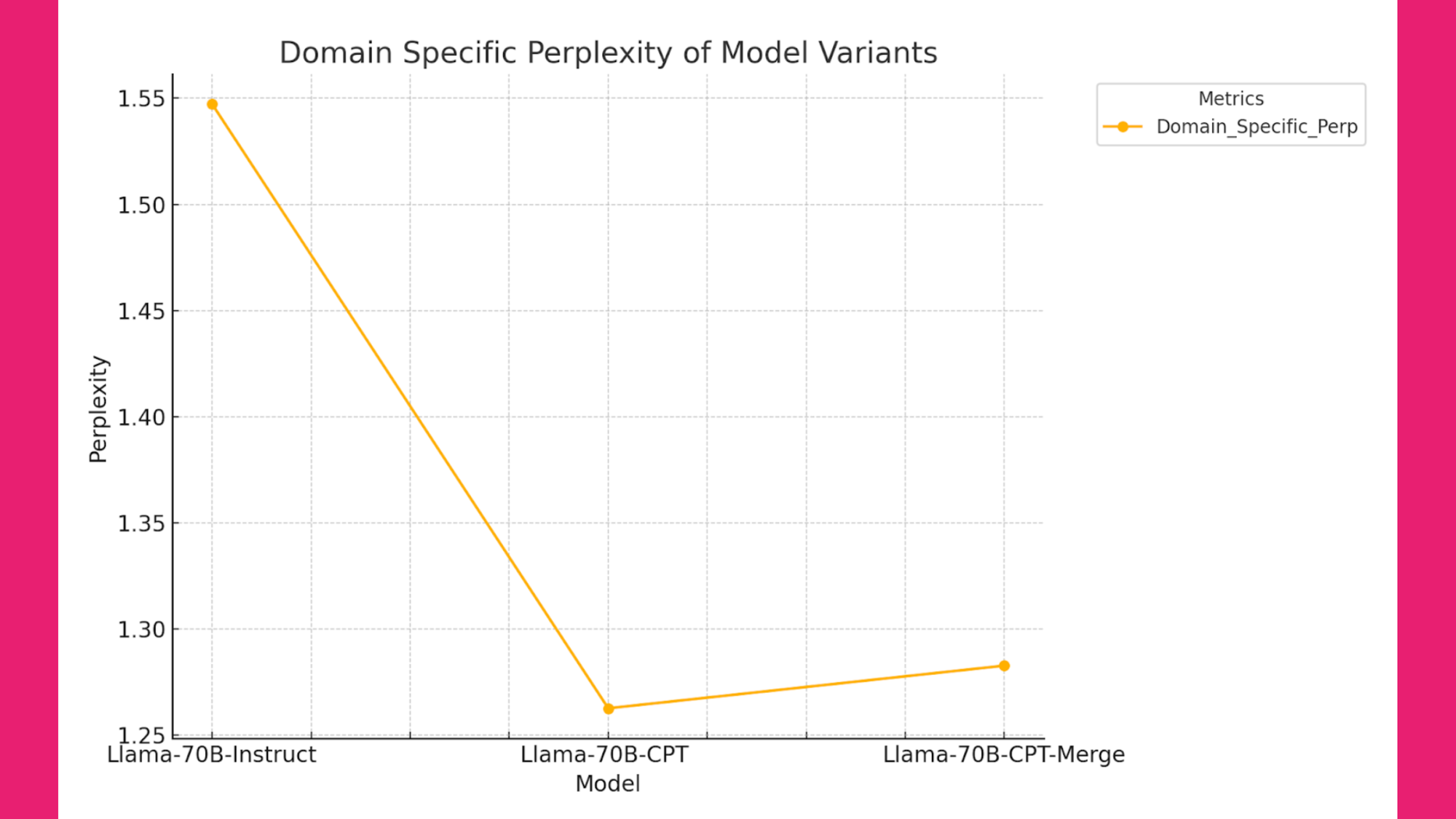
Figure 1: Domain-Specific Perplexity of Model Variants (the lower the better)
Insights from Figure 1:
- CPT reduces perplexity related to SEC data, indicating the model's improved understanding and adaptation to this specific domain.
- Merging the CPT model with the Llama3-Instruct version increases perplexity slightly, likely due to reintroducing some of the lost chat capabilities.
- Despite a slight increase in perplexity post-merging, the final model maintains a lower perplexity compared to the original, demonstrating effective domain adaptation while retaining chat capabilities. This indicates that merging models does not compromise the infused domain knowledge gained during CPT. As illustrated in Figures 2, 3, and 4, Model Merging can enhance instruction-following capabilities. This flexibility is invaluable for our objectives, as it allows us to combine domain-specific expertise with improved instruction-following abilities – without sacrificing performance.
As illustrated in Figure 2 below, for domain-specific evaluations, we test the model's performance on extractive numerical reasoning tasks – namely a subset of TAT-QA and ConvFinQA (which are not precisely related to SEC data but still relevant for evaluating domain-specific performance).
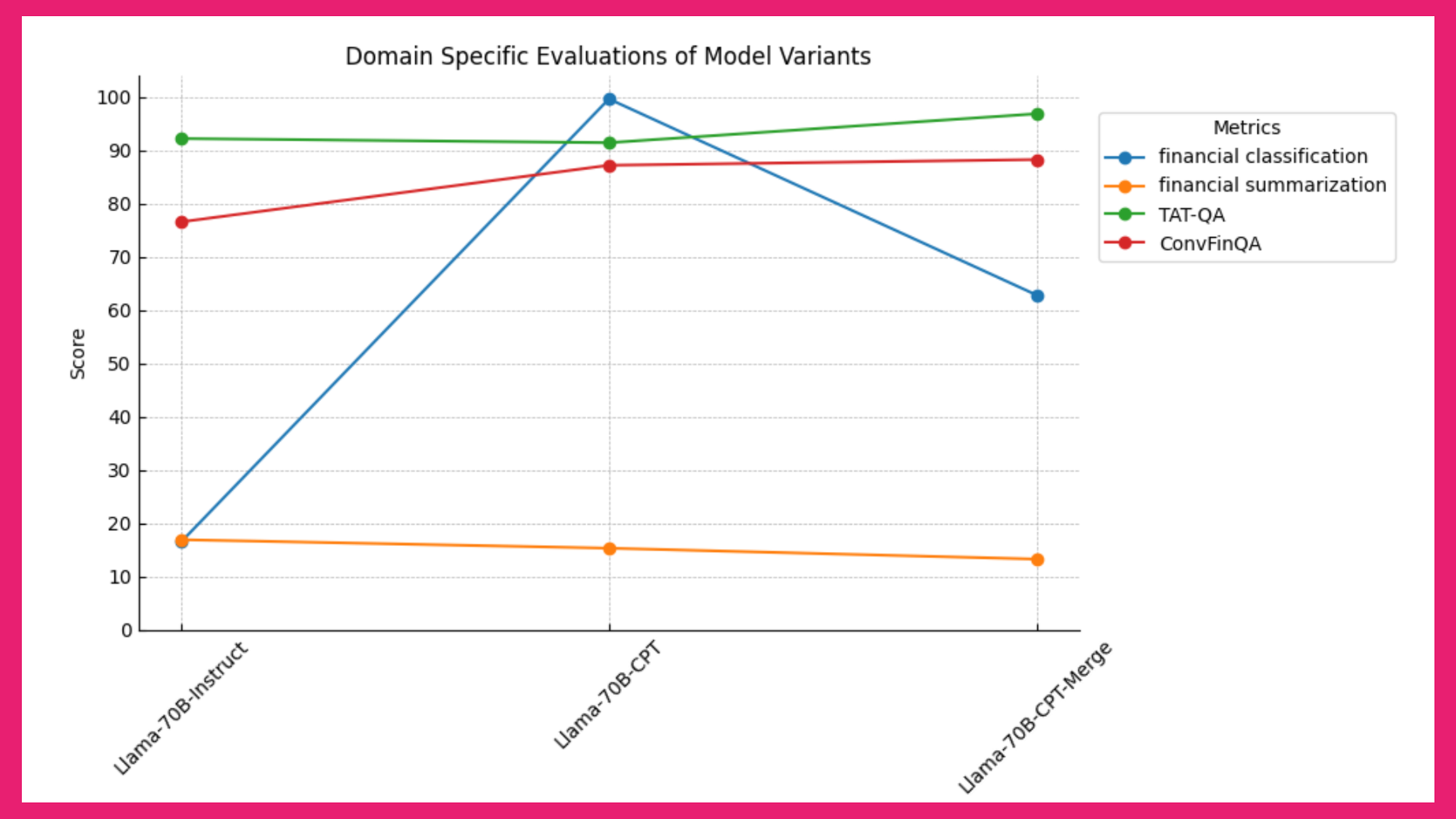
Figure 2: Domain-Specific Evaluations of Model Variants
Insights from Figure 2:
- For ConvFinQA, there is a clear improvement in performance after CPT and further improvement after merging with the instruct model.
- For TAT-QA, significant improvement is observed only after merging, likely due to its specialization in hybrid tabular and textual content, which is less represented in SEC data.
- For the financial classification, where the model categorizes texts as premises or claims, we see very significant accuracy improvements after CPT, nearing a perfect score and indicating that the model learns new tasks effectively from the unsupervised training on SEC data. Merging loses some accuracy but still sits very comfortably above the Instruct baseline.
- For the financial text summarization task, the consistent ROUGE-1 scores across all checkpoints suggest that training on SEC data does not improve performance, possibly due to the baseline model's already strong capabilities and the inherent limitations of ROUGE, which relies on potentially imperfect reference summaries.
- These results highlight the importance of merging models to recover general capabilities, demonstrating how merging can enhance performance in specialized tasks by reintroducing broader knowledge and capabilities.
General Evaluations Metrics
The following Figure 3 illustrates the performance comparison, based on general evaluation metrics using the Eval Harness in full precision.
We focused on an updated version of the Nous Research benchmark consisting of the following metrics:
- BIG-bench
- AGIEval
- GPT4all (a combination of hellaswag,openbookqa,winogrande, arc_easy,arc_challenge,boolq,piqa)
- TruthfulQA
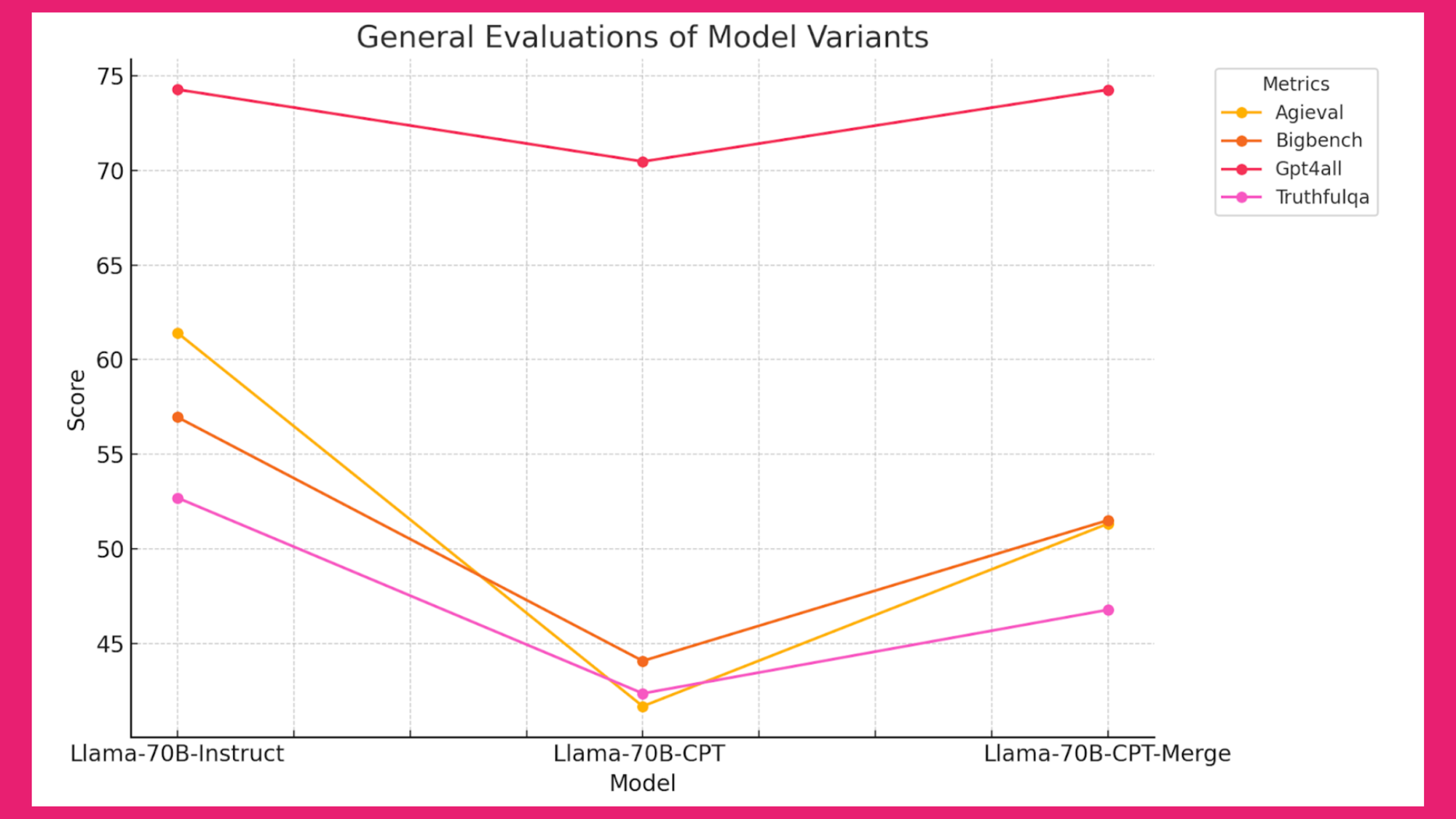
Figure 3: General Evaluations of Model Variants
Insights from Figure 3:
- CPT of Llama-70B-Instruct, resulting in Llama-70B-CPT, demonstrates a drop in general evaluation scores across all metrics (AGIEval, BigBench, GPT4all, TruthfulQA). This indicates potential catastrophic forgetting
- The drop in performance is most prominent in GPT4all and AGIEval metrics, highlighting the challenge of maintaining general capabilities while adapting to new domains
- Merging Llama-70B-CPT with the original Llama-70B-Instruct model using the TIES method (resulting in Llama-70B-CPT-Merge) significantly recovers the lost general capabilities
- This recovery is evident across all metrics, suggesting that Model Merging can effectively mitigate the catastrophic forgetting observed during Continual Pre-Training
- These findings underscore the importance of Model Merging in maintaining a balance between domain adaptation and general capabilities, making it a valuable technique for Continual Pre-Training processes.
In the context of CPT, it’s crucial to measure general perplexity (Figure 4 below) to evaluate the model's performance. It’s important to know how well the model can work with the previous knowledge. Perplexity measures on the following general datasets are used:
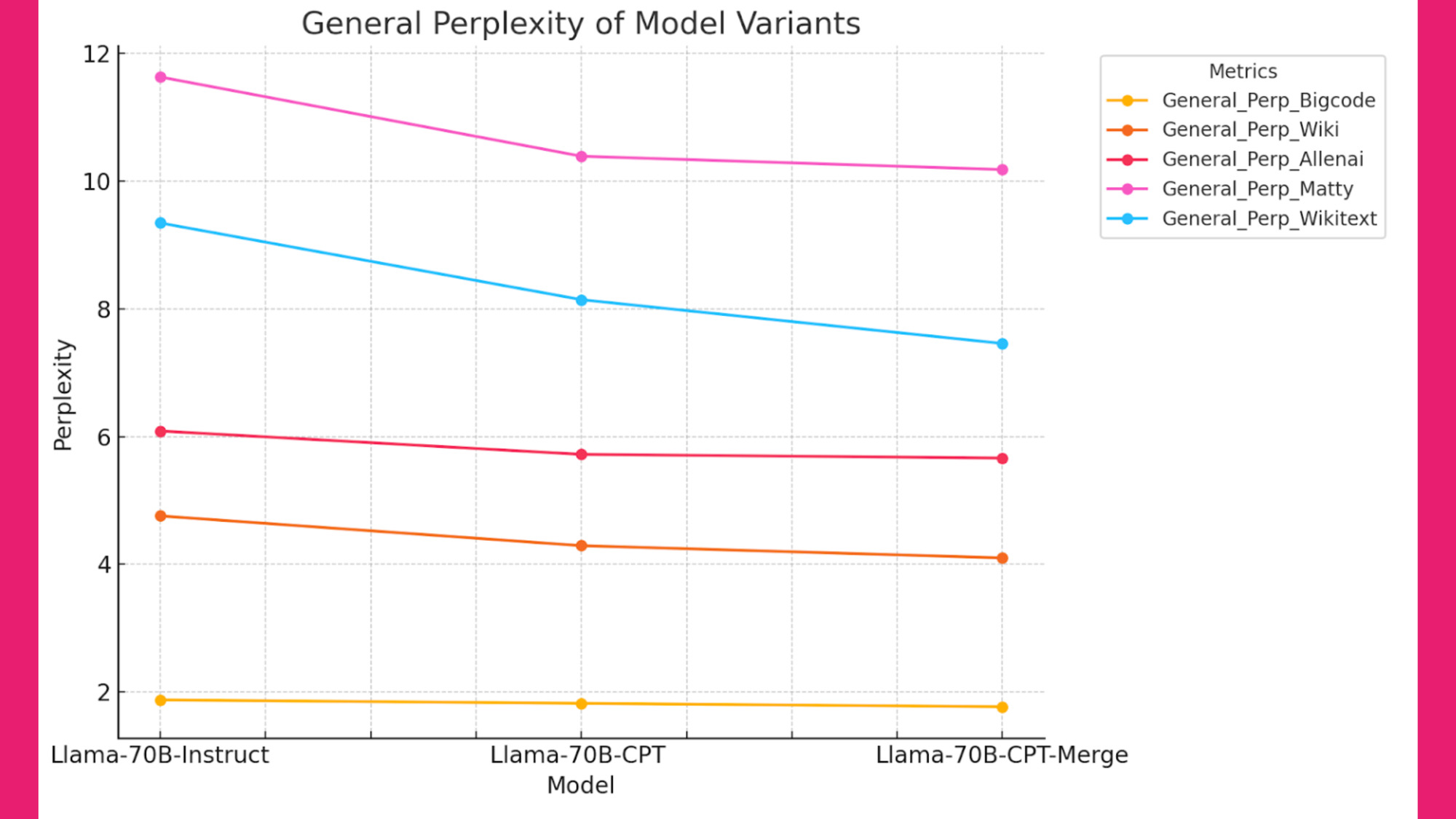
Figure 4: General Perplexity of Model Variants
Insights from Figure 4:
- CPT with a substantial amount of SEC domain-specific tokens (20B) reduces perplexity across all general datasets, indicating improved predictive capabilities.
- This could be due to the nature of the SEC data.
- The model maintains familiarity with general domains even after extensive domain-specific training, as indicated by the stable perplexity metrics for general text shown in the graph. This demonstrates that CPT does not degrade the model's general knowledge, although it may reduce certain capabilities. As seen in Figure 3, we propose that future work on better SFT adaptations can help restore the model's instruction-following capabilities, leveraging the retained knowledge.
Discussion & Future Work
Continual Pre-Training (CPT) of large models like the Llama-3-Instruct-70B variant presents significant challenges but proves to be extremely effective in enhancing domain-specific capabilities. The complexity of maintaining and optimizing such large-scale models requires advanced infrastructure and efficient management systems. Managed SLURM clusters, such as AWS HyperPod, provide the necessary computational resources and orchestration capabilities to streamline these processes, improving the efficiency and scalability of large model training.
CPT, when combined with Model Merging techniques, shows very promising results in creating better-performing models. Merging helps recover general capabilities that might be lost during domain-specific training, thus balancing specialized performance with overall robustness. This dual approach not only mitigates catastrophic forgetting but also enhances the model's applicability across diverse tasks.
Releasing two models now, with more to come
With today's release of two SEC models, w're launching a series of
Arcee AI model releases that will focus on:
- developing the best chat models customized for specific domains
- showcasing the power of training paired with Model Merging.
Below is an in-depth look at some of the research paths we're exploring as we work to continually build the most performant and efficient domain-specific models We invite the community to explore these techniques and contribute to the ongoing efforts in alignment and merging – fostering collaborative advancements in the development of domain-specific chat models 🙌
Aligning CPT Models with SFT, DPO, and other alignment methods
We plan to address catastrophic forgetting by aligning CPT models with general Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning from Human Feedback (RLHF). While Model Merging can recover some lost knowledge, integrating these alignment techniques will further minimize catastrophic forgetting and help realize the next version of our models.
Improving the CPT Data Processing Layer
We will enhance data filtering methods to better manage catastrophic forgetting and optimize data mixing with general data – which is crucial for handling large-scale models like the 70B.
Exploring Model Merging Further
We're investigating advanced techniques and methodologies for Model Merging to maximize the retention of general capabilities while enhancing domain-specific performance.