DistillKit v0.1 by Arcee Labs: The Technical Paper
Read the DistillKit v0.1 by Arcee AI Technical Paper: our new open-source tool that's set to change how we create and distribute Small Language Models (SLMs).

Arcee AI's mission is to enable users and businesses to train cost-effective, secure, performant, and domain-specific Small Language Models (SLMs). In pursuit of this mission, we’re excited to announce the release of DistillKit.
Introducing DistillKit
DistillKit is an open-source research effort in model distillation by Arcee AI. Our goal is to provide the community with easy-to-use tools for researching, exploring, and enhancing the adoption of open-source Large Language Model (LLM) distillation methods. This release focuses on practical, effective techniques for improving model performance and efficiency.
Teacher-Student Training: DistillKit's Model Distillation Methods
DistillKit supports two primary distillation methods:
- Logit-based Distillation: Logit-based distillation transfers knowledge from a larger teacher model to a smaller student model by using both hard targets (actual labels) and soft targets (teacher logits). The soft target loss, computed using Kullback-Leibler (KL) divergence, encourages the student to mimic the teacher's output distribution. This method enhances the student model's generalization and efficiency while maintaining performance close to the teacher model. Logit-based distillation uses both hard targets (actual labels) and soft targets (teacher logits). The soft target loss, computed using KL divergence, encourages the student to mimic the teacher's output distribution [1, 2]. This method demonstrates the highest performance gains according to our case studies but requires models to share the same tokenizer. It offers significant improvements over standard training routines.
- Hidden States-based Distillation: Hidden states-based distillation involves transferring knowledge from a larger teacher model to a smaller student model by using intermediate layer representations from both models. This method includes aligning the hidden states of the student model with those of the teacher model, ensuring the student captures similar intermediate features. The process enhances the student's learning by providing richer, layer-wise guidance, improving its performance and generalization [2, 3]. This method allows for cross-architecture distillation, such as distilling a Llama-3.1-70B based model into a StableLM-2-1.6B, providing flexibility in model architecture choices.
DistillKit Initial Release and Features: Supervised Fine-Tuning and Distillation Experiments
The initial release includes the utilization of Supervised Fine-Tuning (SFT) in distillation routines. All vanilla models were trained using the standard SFTTrainer from Hugging Face's TRL training library. Models for comparison were trained using the same hyper-parameters as the vanilla training but were distilled from Arcee-Spark.
We have internal versions utilizing Continued Pre-Training (CPT) and Direct Preference Optimization (DPO) in distillation methods, which will be released after thorough evaluation.
Distillation Experiments and Results
We are also releasing case studies on DistillKit alongside these release notes. Our case study focuses on the following key areas:
- Teacher Model Selection: We chose Arcee-Spark, a powerful general-purpose Qwen-2-7B model variant, as the teacher model. Spark is a strong generalist 7B model, and serves well for distillation into smaller models when using diverse, general datasets.
- Base versus Instruct Student Model: We conducted a series of experiments to distill knowledge from Arcee-Spark into both Qwen2-1.5B-Instruct and base models.
- Effectiveness of Distillation Techniques: We assessed the effectiveness of hidden-state-based and logit-based distillation methods in a general domain, comparing the performance of the vanilla SFT model against the SFT model refined through distillation. Additionally, we analyzed the performance gains by comparing the distilled model with both the teacher models and the vanilla model.
- Domain-Specific Distillation: Finally, we extended our distillation approach to a specific domain, "function calling," utilizing Arcee-Agent as the teacher model.
Further details on the experimental setups, training pipeline, and evaluation benchmarks are provided in the results section.
Performance and Memory Requirements
While the implementation of DistillKit is relatively straightforward, the memory requirements for distillation are higher compared to standard SFT. We are actively working on scaling DistillKit to support models larger than 70B parameters, which will involve advanced techniques and efficiency improvements beyond the scope of this release.
Model Evaluations
For evaluation purposes, all models were based on Qwen2 and assessed using multiple benchmarks from Hugging Face's Open LLM leaderboard. However, our results (via lm-evaluation-harness) consistently differed, often showing much higher performance, so our evaluations should be viewed with this context in mind. Results should not be compared against the leaderboard - and are not intended to be. Real world differences in model performance are likely to be lower than those seen here. The primary goal was to compare existing distillation techniques in DistillKit through ablation studies. For domain-specific evaluation, we used overall accuracy across Berkeley function calling benchmarks to assess LLM's ability to call functions (aka tools).
Experiment Results
In this section, we present the evaluation results of our case studies. These evaluations demonstrate the potential efficiency and accuracy gains of each distillation method, offering valuable insights into their impact on model performance and suggesting promising avenues for future optimizations.
Experiment 1 - Comparison of Distillation Techniques with Vanilla SFT
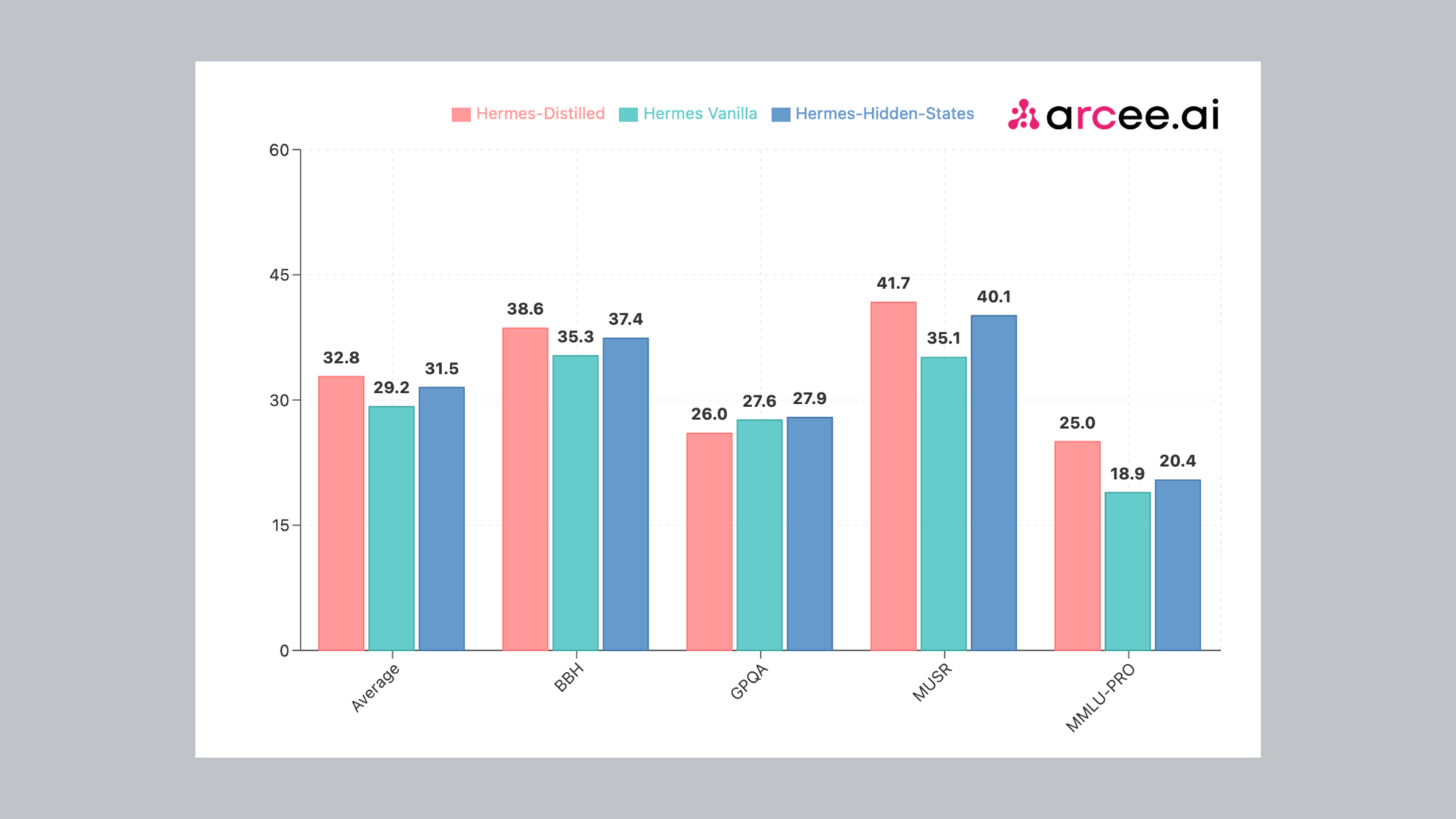
In this experiment, we look at the performance of different models, highlighting the power of distillation. Using Arcee-Spark as the teacher model, we distilled it into Qwen2-1.5B-Base and trained on a carefully curated subset of the Teknium's OpenHermes-2.5 dataset (200k examples).
Our analysis focused on three key models:
- Hermes-Distilled: Refined through a logit-based distillation approach.
- Hermes-Hidden-States: Enhanced using hidden-state-based distillation.
- Hermes Vanilla: The SFT-only version, serving as our baseline, utilizing the same SFT routine and hyper parameters without any distillation.
Both Hermes-Distilled and Hermes-Hidden-States outperformed the SFT-only variant across major benchmarks like BBH, MUSR, and MMLU-PRO. Performance on GPQA was also impressive, with comparable results across all three models. Notably, the logit-based approach overall delivered superior results over the hidden-state-based method across most benchmarks.
Experiment 2 - Effectiveness of Logit-based Distillation in Generic Domain
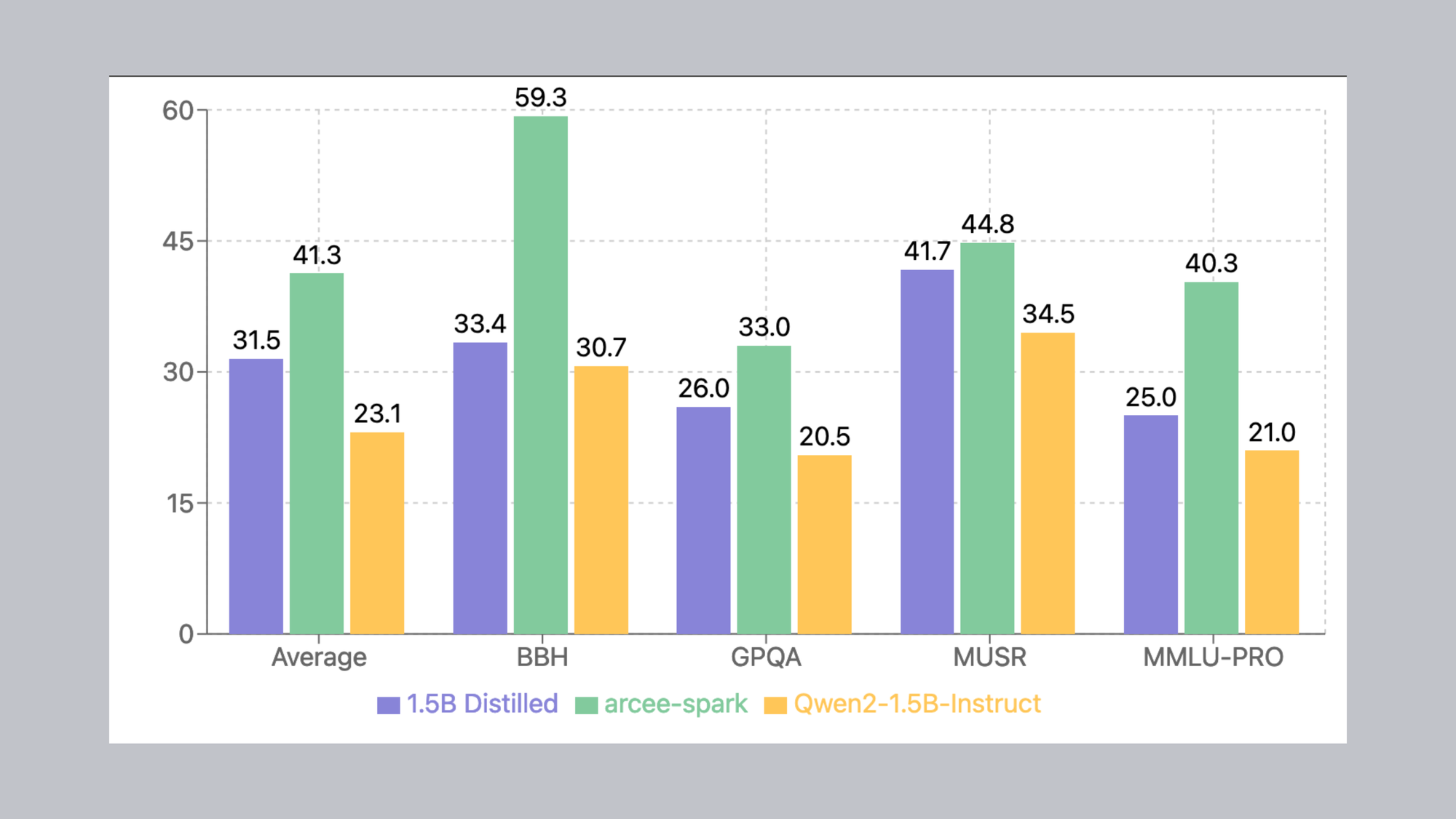
Here we evaluate a 1.5B Distilled model (trained on a 200k subset of WebInstruct-Sub), the teacher model Arcee-Spark, and the baseline Qwen2-1.5B-Instruct model. The distilled model showed a performance improvement over vanilla Qwen2-1.5B-Instruct across all metrics. Additionally, the distilled model's performance was comparable to the teacher model, particularly on MUSR and GPQA benchmarks.
Experiment 3 - Distillation on Instruct versus Base Student Models
The 1.5B-Instruct-Distilled (logit based) model showed marked performance improvements over their vanilla counterparts on MMLU. These were trained on WebInstruct-Sub, a dataset which excels at knowledge retrieval.

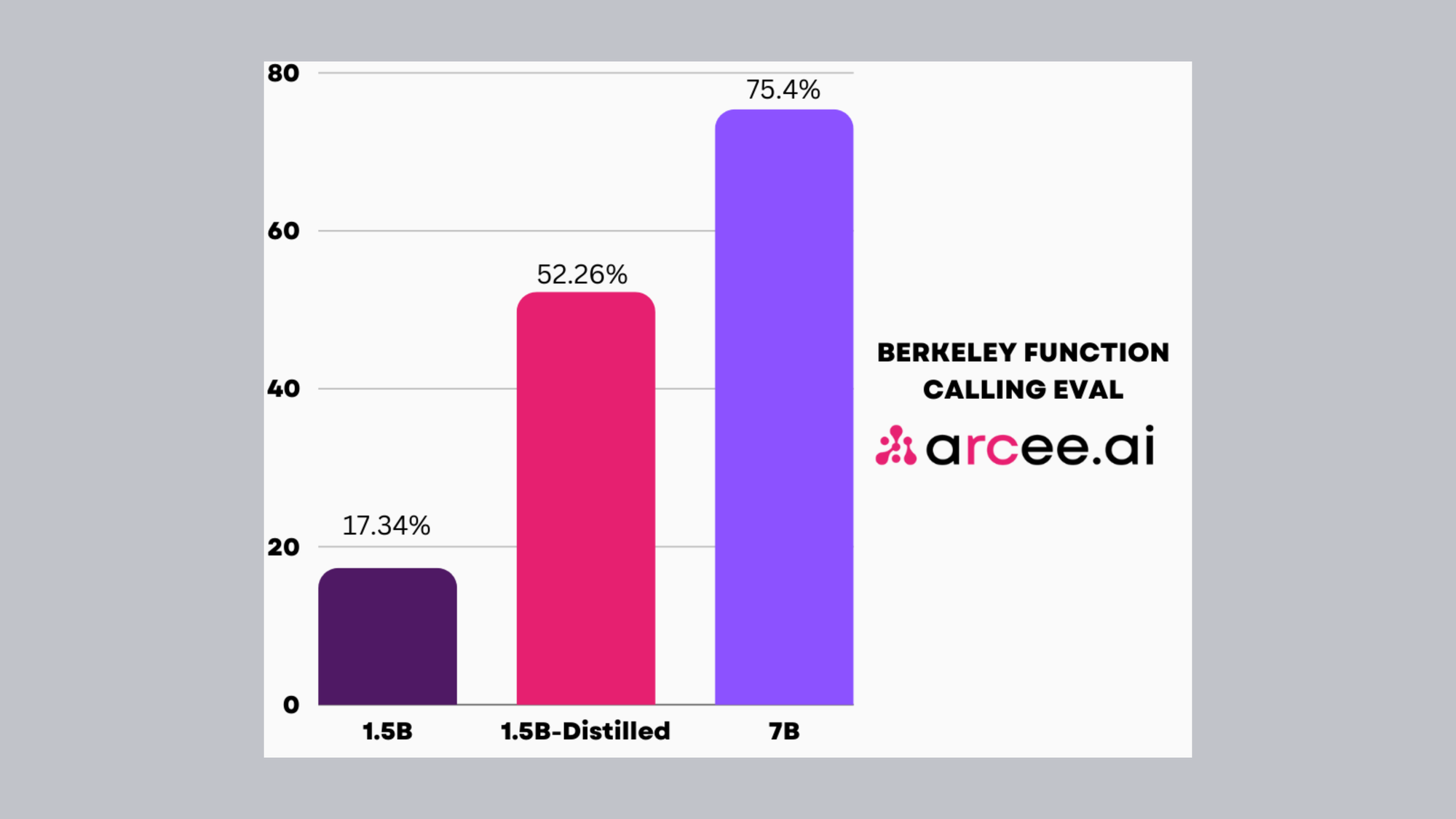
Experiment 4 - Effectiveness of Domain-specific Distillation
Distilling Arcee-Agent into Qwen2-1.5B-Instruct, using the same dataset that initially trained the teacher model. Arcee-Agent, a 7B parameter model engineered for function calling and tool use, showcased substantial performance gains through distillation. These results highlight the potential of using the same training data for both the teacher and student models, unlocking even greater performance improvements. Additionally, this approach demonstrates the effectiveness of distillation not only for general-purpose capabilities but also for domain-specific tasks.
Main Take-aways
Both logit-based and hidden states-based distillation methods show improvements over standard SFT across most benchmarks. The performance uplift is consistent across a variety of datasets and training conditions.
- General-Purpose Performance Gain: Training on subsets of openhermes (200k examples), WebInstruct-Sub (250k examples), and FineTome (100k examples) show encouraging performance improvements. Performance gains in MMLU and MMLU-Pro benchmarks demonstrate promising improvements in knowledge absorption for SLMs.
- Domain-Specific Performance Gain: Significant performance gains were observed when distilling models for domain-specific tasks. Notably, distilling Arcee-Agent into Qwen2-1.5B-Instruct using the same data that it was initially trained on demonstrated substantial improvements. This suggests that using the same training dataset for distillation as was used for the teacher model can lead to higher performance gains.
Arcee-Labs
This release marks the debut of Arcee-Labs, a division of Arcee AI dedicated to accelerating open-source research. Our mission is to rapidly deploy resources, models, and research findings to empower both Arcee AI and the wider community.

In an era of increasingly frequent breakthroughs in LLM research, models, and techniques, we recognize the need for agility and adaptability. Through our efforts, we strive to significantly contribute to the advancement of open-source AI technology and support the community in keeping pace with these rapid developments.
Future Directions
We are excited to see how the community will use and improve DistillKit. It is quite simple in its current form, and can be easily adapted for many use cases and training scenarios. Future releases will include CPT and DPO distillation methods, and we welcome community contributions in the form of new distillation methods, training routine improvements, and memory optimizations.
For more information and to get started, visit our repository on GitHub. We encourage you to share your findings, improvements, and suggestions with the community.
