Arcee Releases Commercial Product to Contextualize Language Models
Emerging out of intensive research and development, the Arcee team is excited to release our commercial product to contextualize language models in the Arcee platform.

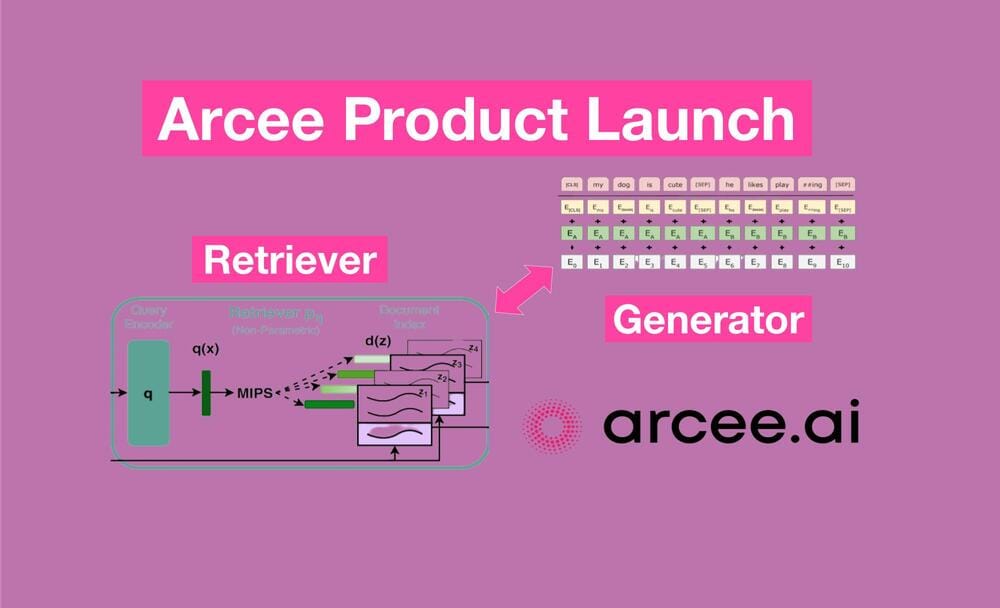
Emerging out of intensive research and development, the Arcee team is excited to release our commercial product to contextualize language models in the Arcee platform.

The Arcee Mission - Domain Adapted Language Models
We at Arcee are all about the domain specialization of language models. We believe in a world where millions if not billions of domain specialized language models exist alongside general language models. Domain Adapted Language Models (DALMs) will operate in niche areas of the business world where proprietary AI is required by the organizations that wield them.
The Arcee Process
In order to create Domain Adapted Language models at Arcee, we follow a two step process - domain pretraining, and the training of end to end retrieval augmented generation systems.
Domain Pretraining
Domain pretraining involves the training of the base generator of a language model on text corpora. This step is important if the base generator has not learned the vocabulary of the target domain such as internal company acronyms and proprietary concepts.
We use techniques from continual pretraining to combat against loss of generality from catastrophic forgetting.

End-To-End Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) involves the process of fetching relevant documents to provide as context to a large language model (LLM) that is completing the answer to a query. RAG systems typically are deployed with general retriever models that are powering general LLMs. While this approach works well on general web language, there are significant improvements to be made by training the retrieval model jointly with the generator in an end-to-end RAG system (E2E RAG).

E2E RAG propagates the loss calculated by the generator during training through to the context that the generator is receiving, sending a signal that the retriever can learn from and improve. Through this process both the generator and retriever become aware of one another and create a contextualized system.
In order to train a RAG system end to end, you hook up your base generator to relevant context documents. If you do not have gold QA pairs for relevant passages, we auto generate QA pairs.

We have seen significant improvements in the evaluation of E2E RAG systems over their general counterparts, especially when dealing with large, domain specific contexts. We have released our research repository open core alongside our commercial offering.
Serving DALM Models in Production
Training Domain Pretrained (DPT) Models
While we open source the DPT models that we pretrain at Arcee for the community, we also provide tools and orchestration software for you to train your own DPT models on corpora. You can estimate the cost of training various DPT models based on billions of tokens and billions of model parameters. The primary challenges with training DPT models involve having the right approach, and more importantly, access to enormous amounts of GPU resources to make sure that your pretraining completes within a relevant timeframe.
Training and Serving E2E RAG Models
While we open source our E2E RAG training pipeline, we also provide infrastructure to train and serve DALM models at scale.
During training, we make sure that optimal GPUs are available and deployed to train your model with optimal training parameters and GPU memory. We provide dashboards for you to monitor your training and APIs for you to automate your training processes.
During inference, we serve contexts in a scalable vector database alongside autoscaling inference of your DALMs retriever models. We stand up indexing APIs to autoscale as you are adding new context documents to a context that has any trained retrievers attached to it. We simultaneously scale the generator model. And most importantly, we serve the retriever models and the generator next to each other so additional inference latency is not realized when posting vectors across the wire, a latency hiccup that is common among general LLM + general retriever combinations.
Along with these important backend backbones, we provide dashboards for you to monitor the inference of your DALM models, and the evolution of the context that is powering your LLMs.
VPC Deployments
When building proprietary AI, we know the importance of keeping data behind the wall of your company’s VPC and that is why we have built the Arcee platform to be completely deployable, so you can host it privately and protect your internal intellectual property and your customers' information.
The Arcee Product in Sum
At Arcee we are all about building Domain Adapted Language Models, which unlock deep understanding of the context that they have been trained to understand. In-domain language models will underpin the most impactful solutions of AI in industry.
We are built with an open core, so the community can build DALM models with our public DALM repository and public DPT models.
We complement our public presence with a deployable platform, so you can bring your DALM models to production faster and with greater efficacy and reliability.