Why Methods Like QLoRA Fall Short in Domain Knowledge Injection
Arcee's research shows that the Standard Continual Pre-Training (CPT) approach performs better than QLORA-based CPT.


Domain knowledge probing, A.K.A Continual Pre-training (CPT), is a process by which new knowledge is systematically incorporated into a pre-trained Large Language Model (LLM). CPT traditionally demands adjusting a massive set of parameters–often scaling into the billions–to effectively integrate vast amounts of domain-specific data.
The Role and limitations of Parameter-Efficient Fine-tuning (PEFT)
While Parameter Efficient Fine-Tuning (PEFT) techniques like QLoRA promise significant efficiencies by approximating necessary gradients with a much lower rank matrix—thereby reducing the number of parameters needed for tuning—these methods have critical limitations when used in CPT.
Where QLoRA shines: Instruction tuning and preference alignment
QLoRA excels in areas that do not demand the addition of new knowledge to the LLM, such as instruction tuning and preference alignment methods like Direct Preference Optimization (DPO). These applications involve subtle adjustments to optimize the model's existing knowledge base to align outputs with specific instructions or preferences. The datasets used for these tasks are generally much smaller than those required for CPT. For instance, instruction tuning and DPO often utilize datasets that are less complex and significantly smaller in scale, focusing more on refining how the model applies its pre-existing capabilities rather than expanding them.
Why QLoRA Is inadequate for CPT
Despite its effectiveness in specific scenarios, QLoRA is unsuitable for CPT where the goal is to integrate extensive new knowledge. Research from studies like Less is for more alignment and DARE indicates that the parameter adjustments during instruction tuning are relatively minor compared to those in CPT. Furthermore, insights from ModuleFormer reveal that QLoRA and similar PEFT methods are incapable of introducing the significant new knowledge required in CPT.
Empirical evaluation: Insights from Arcee.ai
To objectively evaluate these theories, we conducted an experiment at Arcee.ai using a Security and Exchange Commission (SEC) dataset with 2.5 billion tokens. We applied CPT over 1 epoch in two configurations:
- Mistral-7B-Instruct-v0.2 with standard CPT
- Mistral-7B-Instruct-v0.2 with QLoRA-based CPT
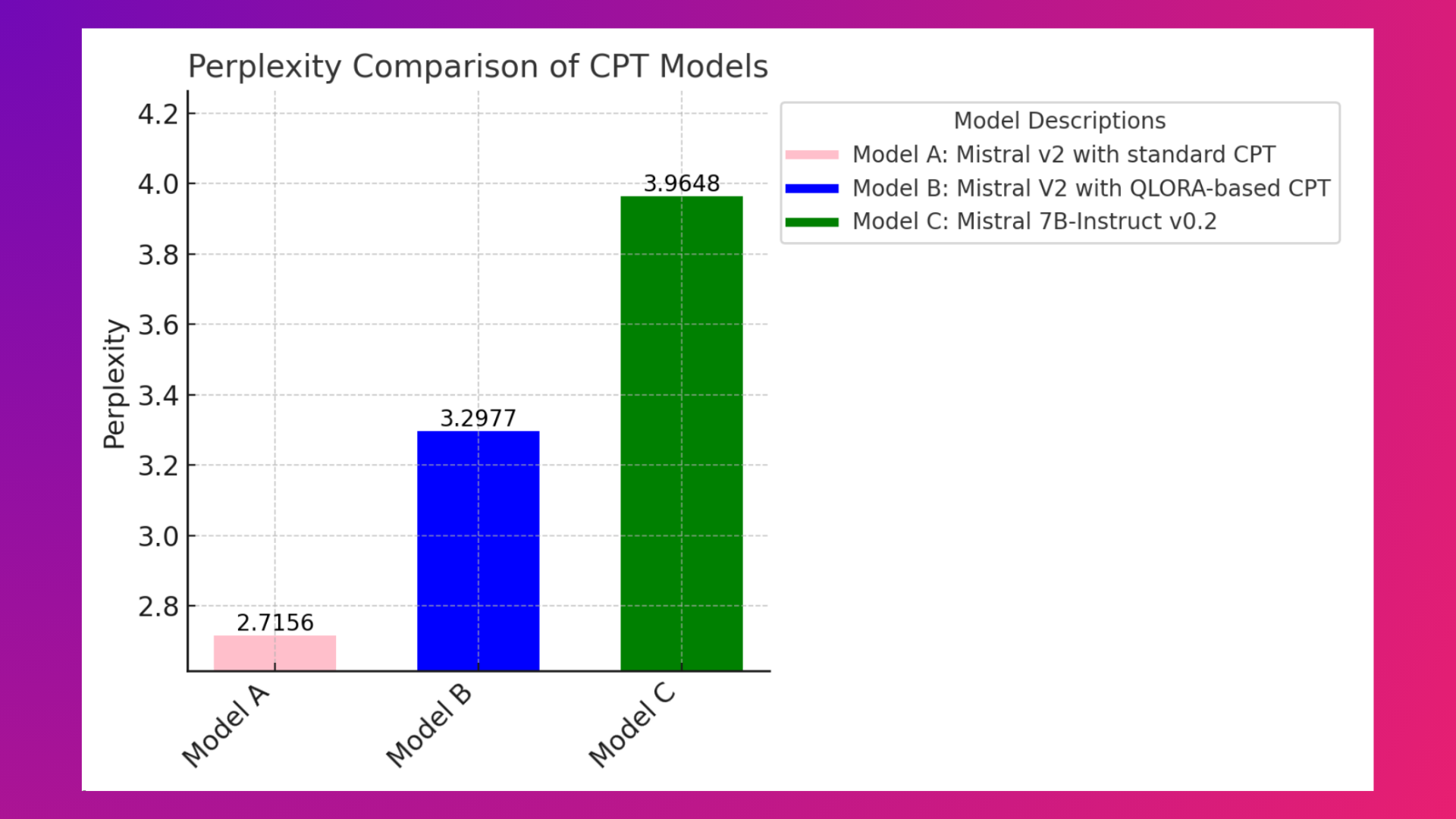
Then, we evaluated both models using the perplexity metric, where a lower metric indicates a better model. The perplexity measurements on a test set are illustrated in the graph below:
- arcee-ai/sec-mistral-7b-instruct-v2: 2.7156
- arcee-ai/sec-mistral-instruct-v2-qlora: 3.2977
- mistralai/Mistral-7B-Instruct-v0.2: 3.9648
These findings indicate that the Standard CPT approach performs better than the QLoRA-based CPT approach. This underscores the critical limitation of QLoRA and similar PEFT methods: they are not equipped to handle the demands of CPT, where extensive new knowledge must be integrated into LLMs.
Conclusion
While PEFT methods like QLoRA provide significant advantages in terms of efficiency and speed for specific fine-tuning tasks, they are unsuitable for replacing CPT in contexts requiring the integration of extensive new knowledge. The quest for more effective methods to achieve efficient and extensive continual pre-training remains a vital area for future LLM research and development.